pyVideoTrans 技术架构与实现原理
pyvideotrans 是一款功能强大的开源视频翻译配音工具(v4.03),能够将视频自动翻译并配上目标语言的语音。其核心设计理念是模块化、多线程流水线,通过灵活的标志位组合支持多种工作模式。
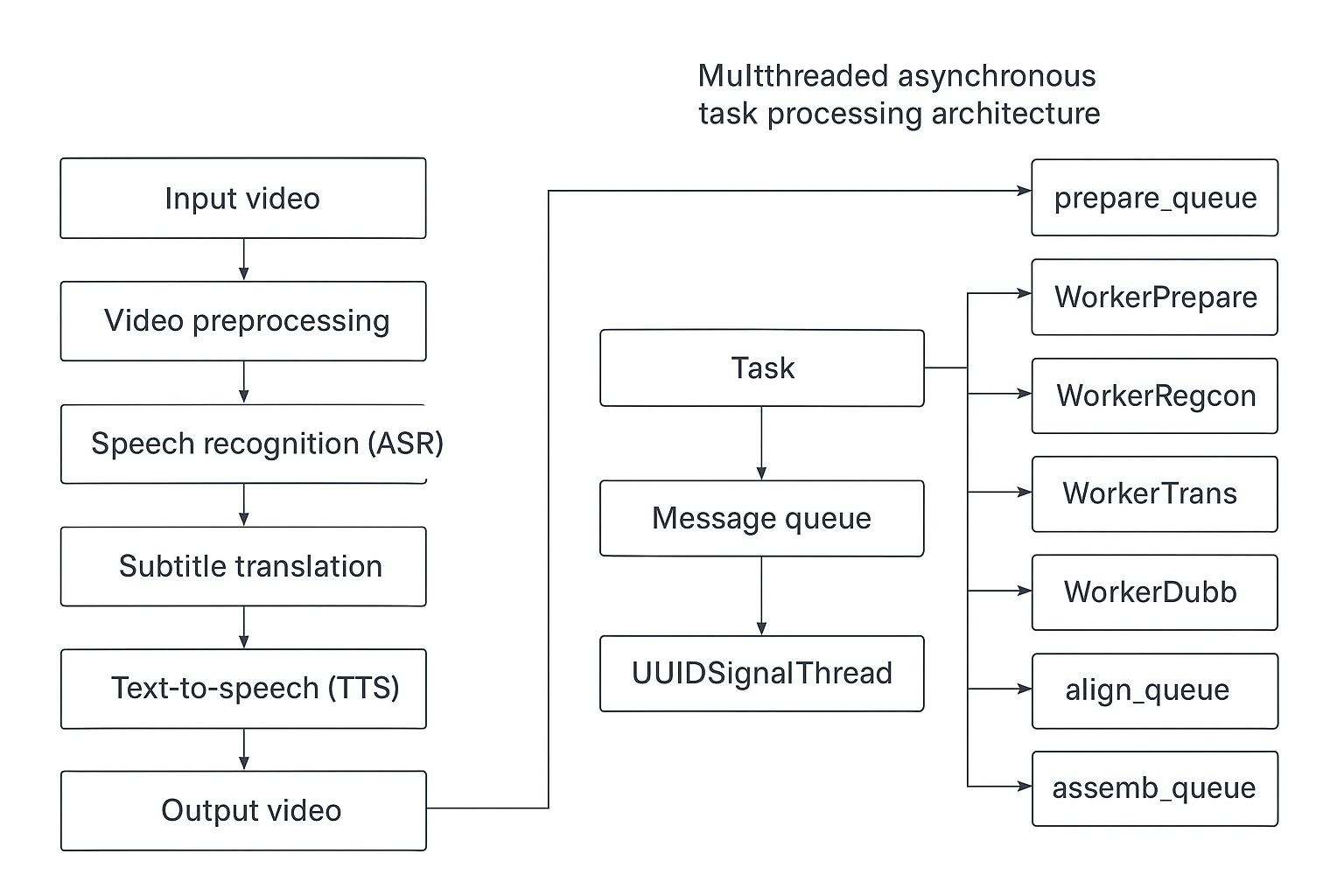
一、核心处理流程
软件将视频翻译配音过程分解为 9 个独立阶段,形成一条自动化的处理流水线。每个任务通过 5 个布尔标志位(should_recogn、should_trans、should_dubbing、should_hebing、should_separate)控制哪些阶段被跳过,从而支持不同的工作模式。
1.1 九个处理阶段
| 阶段 | 方法 | 职责 |
|---|---|---|
| ① 预处理 | prepare() | 从视频中分离无声视频流和原始音频流;可选人声/背景分离(UVR/Spleeter);可选降噪;创建缓存目录和输出目录 |
| ② 语音识别 | recogn() | 调用 ASR 引擎(默认 Faster-Whisper,支持 22 种渠道)将音频转录为带时间戳的 SRT 字幕;可选标点恢复、LLM 重新断句 |
| ③ 说话人分离 | diariz() | 调用说话人分离模型(built、ali_CAM、pyannote、reverb 四种后端),将字幕按说话人归类标注 |
| ④ 字幕翻译 | trans() | 将原始语言 SRT 字幕通过翻译渠道(24 种渠道)翻译为目标语言字幕;支持双语字幕输出 |
| ⑤ 配音 | dubbing() | 根据目标语言字幕内容和时间戳,调用 TTS 引擎(34 种渠道)逐条生成配音音频;支持声音克隆(从原始音频截取参考片段) |
| ⑥ 音画对齐 | align() | 通过 SpeedRate 类处理:配音加速、视频慢放、去除字幕间隙静音、字幕音频强制对齐;完成后可选调节音量 |
| ⑦ 二次识别 | recogn2pass() | 对配音音频再次进行 ASR,生成时间轴精确且短小的字幕(仅在启用配音且非双字幕嵌入时执行) |
| ⑧ 最终合成 | assembling() | 将无声视频流、配音音频、背景音乐、目标语言字幕合并为最终视频文件(ffmpeg) |
| ⑨ 收尾 | task_done() | 将输出文件从临时目录移动到指定输出目录,清理临时文件,发送完成通知 |
1.2 流程控制标志位
定义在 videotrans/task/_base.py:20-29,五个标志位在 TransCreate.__post_init__() 中根据配置自动计算:
should_recogn: bool # 是否需要语音识别(无已有字幕则为 True)
should_trans: bool # 是否需要翻译(源语言 ≠ 目标语言则为 True)
should_dubbing: bool # 是否需要配音(选择了配音角色且非 'No' 则为 True)
should_hebing: bool # 是否需要嵌入合并(非 'tiqu' 模式且有配音或字幕嵌入则为 True)
should_separate: bool # 是否需要人声背景分离1.3 模式切换示例
不同功能通过标志位组合实现:
| 功能 | should_recogn | should_trans | should_dubbing | should_hebing |
|---|---|---|---|---|
| 视频翻译配音(标准模式) | ✓ | ✓ | ✓ | ✓ |
| 视频/音频转字幕(tiqu) | ✓ | 可选 | ✗ | ✗ |
| 字幕配音 | ✗ | ✗ | ✓ | ✓ |
| 仅翻译字幕文件 | ✗ | ✓ | ✗ | ✗ |
1.4 任务子类体系
BaseTask 有四个具体子类,各自对应不同的使用场景:
| 子类 | 文件 | 继承的 TaskCfg | 使用场景 |
|---|---|---|---|
TransCreate | task/trans_create.py | TaskCfgVTT | 完整视频翻译配音(标准模式 / tiqu 提取模式) |
SpeechToText | task/speech2text.py | TaskCfgSTT | 批量语音转字幕 |
DubbingSrt | task/dubbing.py | TaskCfgTTS | 批量为字幕配音 |
TranslateSrt | task/translate_srt.py | TaskCfgSTS | 批量翻译 SRT 字幕 |
二、任务配置数据类体系
v4.03 重构了任务配置为分层继承的 @dataclass 体系(videotrans/task/taskcfg.py,261 行):
@dataclass TaskCfgBase ← 通用字段(路径、语言代码、缓存目录等)
├── @dataclass TaskCfgSTT ← 语音识别相关字段(recogn_type, model_name, rephrase 等)
├── @dataclass TaskCfgTTS ← 配音相关字段(tts_type, voice_role, voice_autorate 等)
├── @dataclass TaskCfgSTS ← 翻译相关字段(translate_type)
└── @dataclass TaskCfgVTT ← 视频翻译全量字段(继承 STT + TTS + STS,新增视频特有字段)辅助数据类:
| 数据类 | 文件 | 用途 |
|---|---|---|
InputFile | task/taskcfg.py | 输入文件元信息(name, dirname, noextname, basename, ext, uuid, target_dir),支持 dict 式访问 |
SignMsg | task/taskcfg.py | 信号消息体(type, uuid, text),提供 is_stop() 和 is_error() 方法判断状态,在 Worker 线程与主线程间传递 |
SrtItem | task/taskcfg.py | 单条字幕数据(text, start_time, end_time, startraw, endraw, line, time, spk, filename) |
SrtItem 支持同时用属性访问(item.text)和字典访问(item['text']),并可通过 items() 迭代。
三、多线程异步任务处理架构
软件采用基于 "生产者-消费者"模式 的多线程多队列架构。MultVideo 线程充当生产者,将任务对象推入流水线的第一个队列;9 种专用 BaseWorker 子类作为消费者,各自监听专属队列。
3.1 队列流水线
MultVideo (生产者)
│
app_cfg.prepare_queue
▼
WorkerPrepare (×N)
┌────────┼────────┐
│ should_recogn ? │
▼ ▼ ▼
regcon_queue trans_queue dubb_queue / assemb_queue / taskdone_queue
│
▼
WorkerRegcon (×N)
│
diariz_queue
│
▼
WorkerDiariz (×N)
┌────┼────┐
▼ ▼ ▼
trans_queue dubb_queue assemb_queue / taskdone_queue
│
▼
WorkerTrans (×1)
┌────┼────┐
▼ ▼ ▼
dubb_queue assemb_queue taskdone_queue
│
▼
WorkerDubb (×1)
│
align_queue
│
▼
WorkerAlign (×1)
┌────┼────┐
▼ ▼ ▼
regcon2_queue assemb_queue taskdone_queue
│
▼
WorkerRegcon2Pass (×1)
┌────┼────┐
▼ ▼
assemb_queue taskdone_queue
│
▼
WorkerAssemb (×N)
│
taskdone_queue
│
▼
WorkerTaskDone (×1)
│
(end)3.2 Worker 基类设计
所有工作线程继承自 BaseWorker(QThread)(videotrans/task/job.py:13-66):
class BaseWorker(QThread):
def __init__(self, name, queue):
self.name = name
self.queue = queue
def run(self):
while True:
if app_cfg.exit_soft: # 全局软退出标志
return
try:
trk = self.queue.get(timeout=1) # 阻塞1秒取任务
except Empty:
continue
if trk.uuid in app_cfg.stoped_uuid_set: # 任务已停止
continue
try:
self.process_task(trk) # 子类实现具体逻辑
except Exception as e:
self.handle_error(e, trk) # 统一错误处理每个子类重写以下方法:
| 方法 | 说明 |
|---|---|
process_task(trk) | 必须 — 执行阶段逻辑,并将 trk 路由到下一个队列 |
get_error_prefix(trk) | 可选 — 返回错误前缀字符串(如 "识别出错[Faster-Whisper]") |
cleanup_on_error(trk) | 可选 — 出错时的清理逻辑 |
handle_error() 统一调用 get_msg_from_except() 解析异常为用户可读信息,然后通过 trk.signal() 发送错误消息。
3.3 Worker 路由决策逻辑
每个 Worker 在执行完 process_task(trk) 后,根据 trk 的标志位决定下一跳队列:
WorkerPrepare → regcon_queue | trans_queue | dubb_queue | assemb_queue | taskdone_queue
WorkerRegcon → diariz_queue (无条件)
WorkerDiariz → trans_queue | dubb_queue | assemb_queue | taskdone_queue (diariz 异常不阻断流程)
WorkerTrans → dubb_queue | assemb_queue | taskdone_queue
WorkerDubb → align_queue (无条件)
WorkerAlign → regcon2_queue | assemb_queue | taskdone_queue (regcon2 仅当有 recogn2pass 属性时)
WorkerRegcon2Pass → assemb_queue | taskdone_queue
WorkerAssemb → taskdone_queue (无条件)
WorkerTaskDone → (终止)3.4 线程数量动态计算
start_thread()(videotrans/task/job.py:206-245)根据 GPU 配置动态决定各 Worker 的实例数:
| Worker | 实例数 | 原因 |
|---|---|---|
WorkerPrepare | 1 ~ 4 | GPU 密集型操作(视频编解码) |
WorkerRegcon | 1 ~ 4 | GPU 密集型(ASR 推理) |
WorkerDiariz | 1 ~ 4 | GPU 密集型(说话人分离) |
WorkerTrans | 固定 1 | API 调用,避免并发限流 |
WorkerDubb | 固定 1 | TTS API 调用,避免并发限流 |
WorkerRegcon2Pass | 固定 1 | 辅助阶段 |
WorkerAlign | 固定 1 | 音画对齐为单线程 |
WorkerAssemb | 1 ~ 4 | GPU 密集型(ffmpeg 编码) |
WorkerTaskDone | 固定 1 | 文件移动/清理 |
task_nums 计算逻辑:优先使用 settings.process_max_gpu 手动指定值;否则根据 multi_gpus + NVIDIA_GPU_NUMS 自动检测(1 GPU = 1,2-3 GPU = 2,≥4 GPU = 4,无 GPU = 1)。
3.5 批量任务提交:MultVideo
MultVideo(QThread)(videotrans/task/mult_video.py,54 行)负责将用户选择的多个视频文件逐个创建 TransCreate 对象并推入 prepare_queue。支持通过 batch_nums 参数控制每批并发数量:
batch_nums == 0:全部任务一次性推入队列(最大并发)batch_nums == 1:逐次推入,每个任务完成后再推下一个batch_nums > 1:每批推入 N 个,等待该批全部完成后再推下一批
3.6 软退出机制
全局标志 app_cfg.exit_soft 设为 True 时,所有 Worker 在下一轮循环中检测并安全退出。app_cfg.stoped_uuid_set 用于标记被手动停止的特定任务 UUID,Worker 在取出任务后跳过这些任务。
四、核心类的设计与继承关系
4.1 类继承体系
@dataclass BaseCon ← videotrans/configure/base.py
│ 基础属性和工具方法
├── @dataclass BaseTask ← videotrans/task/_base.py
│ │ 定义 8 个阶段空方法和 5 个标志位
│ ├── @dataclass TransCreate ← videotrans/task/trans_create.py (~1678 行核心)
│ ├── @dataclass SpeechToText ← videotrans/task/speech2text.py (批量语音识别)
│ ├── @dataclass DubbingSrt ← videotrans/task/dubbing.py (批量字幕配音)
│ └── @dataclass TranslateSrt ← videotrans/task/translate_srt.py (批量字幕翻译)
│
├── @dataclass BaseRecogn ← videotrans/recognition/_base.py
│ │ VAD 音频切分、字幕合并、CJK 处理
│ └── 22 个子类(懒加载) 各 ASR 渠道具体实现
│
├── @dataclass BaseTrans ← videotrans/translator/_base.py
│ │ MD5 缓存、逐行/全文翻译调度
│ └── 24 个子类(懒加载) 各翻译渠道具体实现
│
└── @dataclass BaseTTS ← videotrans/tts/_base.py
│ 异步/多线程并发调度
└── 34 个子类(懒加载) 各 TTS 渠道具体实现所有通道类均为 @dataclass,使用 __post_init__ 初始化而非传统构造函数 __init__。
4.2 BaseCon——顶层基类
videotrans/configure/base.py(296 行)定义了所有类共用的核心能力:
| 方法 | 职责 |
|---|---|
_exit() | 检查是否应停止(exit_soft 或 UUID 在 stoped_uuid_set 中) |
signal(**kwargs) | 向 UI 发送消息(通过 push_queue() → SignalHub。CLI 模式下直接 print) |
_set_proxy(type) | 设置/清除 HTTP 代理(操作 app_cfg.proxy 和环境变量) |
_new_process(callback, title, is_cuda, kwargs) | 在子进程中执行耗时任务(返回 (data, error) 元组) |
_signal_of_process(logs_file) | 通过轮询 JSON 日志文件的 mtime 实时读取子进程进度 |
convert_to_wav() | 音频统一转为 48kHz 立体声 WAV(可选去静音) |
_base64_to_audio() / _audio_to_base64() | Base64 音频编解码 |
_process_callback(data) | 下载进度回调(转发到 signal()) |
BaseCon.__post_init__() 在初始化时自动调用 _set_proxy(type='set') 获取代理配置。
4.3 BaseTask——任务基类
videotrans/task/_base.py:10-167 定义了所有任务子类的阶段空方法和共享工具:
阶段方法(均为空实现,由子类重写): prepare()、recogn()、diariz()、trans()、dubbing()、align()、assembling()、task_done()
注意:
recogn2pass()方法定义在TransCreate中,不在BaseTask基类中。
共享方法:
| 方法 | 职责 |
|---|---|
_unlink_size0(file) | 删除尺寸为 0 的无效文件 |
_save_srt_target(srtstr, file) | 将 SrtItem 列表格式化为 SRT 字符串并写入文件,发送 replace_subtitle 信号 |
check_target_sub(source, target) | 校验翻译前后字幕行数一致性;不一致时按时间轴匹配对齐 |
set_end(succeed=False) | 标记任务结束,成功时发送通知并清理临时文件夹 |
_edgetts_single(target_audio, kwargs) | Edge-TTS 一次性异步配音(带代理回退) |
4.4 TransCreate——视频翻译核心实现
videotrans/task/trans_create.py(约 1678 行)是完整 9 阶段处理逻辑的实现类。关键内部方法:
| 方法 | 职责 |
|---|---|
__post_init__() | 初始化所有文件路径、计算标志位、启动进度计时线程 |
_split_novoice_byraw() | 从原始视频分离无声视频(优先硬件解码 h264_cuvid,回退 libx264) |
_split_audio_byraw() | 从原始视频提取 16kHz 单声道 PCM 音频 + 可选人声/背景分离 |
_tts() | 构建 queue_tts 列表(含 clone 参考音频片段),调用 tts.run() |
_create_ref_from_vocal() | 多线程(ThreadPoolExecutor)裁剪原始音频对应片段作为声音克隆参考 |
_recogn_succeed() | 识别完成后的处理(tiqu 模式下复制文件) |
_back_music() | 将用户上传的背景音乐与配音音频混合 |
_separate() | 将分离出的背景音乐重新嵌入配音音频 |
_process_subtitles() | 处理软/硬字幕嵌入逻辑(单/双字幕、样式设置) |
4.5 子进程通道
为防止 faster-whisper 崩溃导致整个软件退出,Faster-Whisper、Faster-Whisper-XXL 和 Whisper.cpp(以及部分 TTS 引擎如 QWEN3LOCAL_TTS)通过 BaseCon._new_process() 委托给 GlobalProcessManager 在独立子进程中执行。
子进程通过写入 JSON 日志文件来报告进度。BaseCon._signal_of_process() 在守护线程中轮询该日志文件,检测到 mtime 变化时解析 JSON 并通过 signal() 上报。
五、配置系统
软件将配置分为三个层次(videotrans/configure/config.py,902 行),均为 @dataclass:
| 配置类 | 持久化 | 用途 | 示例字段 |
|---|---|---|---|
AppCfg | 纯内存 | 队列、状态、线程控制、运行时上下文 | prepare_queue, exit_soft, stoped_uuid_set, current_status, line_roles, exec_mode, video_codec, onlyone_source_sub, onlyone_target_sub, proxy, SUPPORT_LANG |
AppSettings | videotrans/cfg.json | 全局默认设置、模型列表 | homedir, model_list, vad_type, cuda_com_type |
AppParams | videotrans/params.json | 用户偏好、API 密钥 | source_language, recogn_type, chatgpt_key, voice_role, app_mode |
关键单例变量在模块加载时自动初始化:
app_cfg: AppCfg = AppCfg() # 运行时状态(含 9 个 Queue 实例)
settings: AppSettings = AppSettings() # 从 cfg.json 加载
params: AppParams = AppParams() # 从 params.json 加载5.1 AppSettings 特性
- 支持
settings['key']字典式访问和settings.get('key', default)方法 get()自动对数字类型字段进行类型强制转换(int_type和float_type白名单)_get_defaults()定义了 ~100 个配置项的默认值- 支持连字符字段名映射(如
"initial_prompt_zh-cn"→"initial_prompt_zh_cn")
5.2 AppParams 特性
_get_defaults()定义了 ~100 个用户参数默认值getset_params(update_data)支持批量更新(如check_start()中收集所有 UI 控件值)- API key 类字段统一在此管理,供
is_input_api()校验
5.3 AppCfg 运行时状态
- 9 个
Queue(maxsize=0)(无限容量):prepare_queue~taskdone_queue queue_novice: Dict— 跟踪无声视频分离进度(key=uuid, value='ing'|'end')line_roles: Dict— 存储单视频模式下用户逐行分配的字幕角色child_forms: Dict— 缓存已打开的窗口实例,避免重复创建exec_mode— 执行模式('gui' 或 'cli')video_codec/codec_cache— 视频编解码器缓存onlyone_source_sub/onlyone_target_sub/onlyone_trans— 单视频模式字幕状态SUPPORT_LANG— 支持的语言列表
5.4 环境变量初始化
_set_env() 在模块加载时自动执行(videotrans/configure/config.py:44-72),设置:
MODELSCOPE_CACHE/HF_HOME/HF_HUB_CACHE→ROOT_DIR/modelsQT_API = 'pyside6'PATH追加 ffmpeg/sox 目录OMP_NUM_THREADS = 1HF_HUB_DOWNLOAD_TIMEOUT = 3600HF_HUB_DISABLE_XET = 1
六、GlobalProcessManager——子进程池管理
videotrans/process/signelobj.py(167 行)实现了一个类级别单例的 GlobalProcessManager:
GlobalProcessManager (类级别单例)
├── _executor_cpu: multiprocessing.Pool
│ workers = max(min(available_ram/4GB, 8, cpu_count), 1) ← 基于剩余内存量计算
│ maxtasksperchild = 1 ← 每个子进程执行一个任务后重启,防内存泄漏
│
└── _executor_gpu: multiprocessing.Pool
workers = GPU 数量(优先 settings.process_max_gpu 手动设置)
maxtasksperchild = 16.1 CPU 进程池规模
不再使用固定公式,而是通过 psutil.virtual_memory().available 获取当前系统剩余内存,按每 4GB 一个进程计算,限制在 1~8 之间,且不超过 os.cpu_count()。可通过 settings.process_max 手动覆盖。
6.2 GPU 进程池规模
优先使用 settings.process_max_gpu 手动设置值;否则根据 multi_gpus 和 NVIDIA_GPU_NUMS 自动确定(无显卡 = 1,有显卡但未启用多显卡 = 1,启用多显卡 = min(GPU 数量, 8, cpu_count))。
6.3 任务提交接口
GlobalProcessManager.submit_task_cpu(func, **kwargs) → AsyncResultFutureWrapper
GlobalProcessManager.submit_task_gpu(func, **kwargs) → AsyncResultFutureWrapperAsyncResultFutureWrapper 将 Pool.apply_async 的 AsyncResult 包装为 Future 兼容接口(.result(), .done())。
6.4 使用场景
通过 BaseCon._new_process() 统一调用,用于执行:ASR 推理、TTS 合成、噪声去除、人声分离、说话人分离、标点恢复(均在独立子进程中运行,崩溃不影响主进程)。
七、SignalHub——跨线程消息中心
videotrans/configure/signal_hub.py(33 行)实现了基于 Qt 信号的单例消息传递:
class SignalHub(QObject):
_instance = None
new_message = Signal(str, object) # (uuid, SignMsg)
@classmethod
def instance(cls):
if cls._instance is None:
cls._instance = cls()
return cls._instance
@Slot(str, object)
def post(self, uuid=None, data=None):
self.new_message.emit(uuid, data) # 跨线程自动使用 QueuedConnection消息流
BaseCon.signal(**kwargs)
→ push_queue(uuid, SignMsg(**kwargs)) [configure/config.py]
→ SignalHub.instance().post(uuid, data)
→ new_message Signal (QueuedConnection)
→ WinAction.update_data(uuid, data) [mainwin/_actions.py]
→ 按 type 分发:
'logs'|'error'|'succeed'|'set_precent' → set_process_btn_text()
'edit_subtitle_source' → 弹出 EditRecognResultDialog
'edit_subtitle_target' → 弹出 SpeakerAssignmentDialog
'edit_dubbing' → 弹出 EditDubbingResultDialog
'replace_subtitle' → 更新字幕编辑区
'end' → update_status('end')消息类型枚举
| type | 含义 | 处理逻辑 |
|---|---|---|
logs | 普通日志 | 更新进度条文本 |
error | 错误 | 进度条变红,加入重试队列 |
succeed | 成功 | 进度条变绿,标记完成 |
set_precent | 进度百分比 | text="耗时???百分比" 格式 |
edit_subtitle_source | 弹出原始字幕编辑框 | 单视频模式暂停点① |
edit_subtitle_target | 弹出翻译字幕编辑框 | 单视频模式暂停点② |
edit_dubbing | 弹出配音结果编辑框 | 单视频模式暂停点③ |
replace_subtitle | 替换字幕区域内容 | 批量/单视频共用 |
subtitle | 追加字幕行 | 逐行输出到编辑器 |
end | 任务完成 | 触发 update_status('end') |
disabled_edit | 禁止编辑字幕 | 批量模式下锁定编辑器 |
refreshtts | 刷新 TTS 选择 | 重新设置 TTS 下拉框 |
shitingerror | 试听错误 | 弹出错误提示 |
ffmpeg | ffmpeg 状态 | 更新开始按钮文本 |
八、动态通道加载
videotrans/__init__.py(35 行)提供了通用的懒加载机制:
@dataclass
class ChannelProvider:
name: str # 界面显示名称
imp: str # 模块导入后缀(如 "._whisper" → "videotrans.recognition._whisper")
key_name: str|None # 对应 params.json 中的 API key 字段(用于 is_input_api 校验)
win: str|None # 对应 winform 中的设置窗口名称
def get_class(channel_id=0, provider_type=None, _ID_NAME_DICT=None):
_key = f'{provider_type}-{channel_id}'
if _key in _loaded_modules:
return _loaded_modules[_key]
module = importlib.import_module(f'videotrans.{provider_type}{_module_map.imp}')
for _, obj in inspect.getmembers(module, inspect.isclass):
if obj.__module__ == module.__name__:
_loaded_modules[_key] = obj
return obj三大模块各自的 _ID_NAME_DICT:
| 模块 | 渠道数 | 定义位置 |
|---|---|---|
| 识别 (recognition) | 22 | videotrans/recognition/__init__.py:48-79 |
| 翻译 (translator) | 24 | videotrans/translator/__init__.py:60-90 |
| 配音 (tts) | 34 | videotrans/tts/__init__.py:75-116 |
8.1 统一入口函数
每个模块提供 run() 统一入口,内部通过 get_class() 获取对应渠道类并实例化调用:
# recognition/__init__.py
def run(*, recogn_type, detect_language, audio_file, ...) -> List[SrtItem]:
_cls = get_class(recogn_type, "recognition", _ID_NAME_DICT)
return _cls(**kwargs).run()
# translator/__init__.py
def run(*, translate_type, text_list, source_code, target_code, ...) -> List[SrtItem]:
_cls = get_class(translate_type, "translator", _ID_NAME_DICT)
return _cls(**kwargs).run()
# tts/__init__.py
def run(*, queue_tts, language, tts_type, ...) -> None:
_cls = get_class(tts_type, "tts", _ID_NAME_DICT)
return _cls(**kwargs).run()8.2 API Key 校验
每个模块提供 is_input_api(recogn_type/translate_type/tts_type) 函数,检查对应渠道的 key_name 在 params 中是否已填写。未填写时自动弹出对应的 winform 设置窗口。
8.3 翻译缓存
BaseTrans(videotrans/translator/_base.py)实现了基于 MD5 的翻译缓存:
- 缓存 key =
md5(channel_name + api_url + model + source_lang + target_lang + text) - 缓存文件存储在
{TEMP_ROOT}/translate_cache/ - 写入接口
_set_cache(),读取接口_get_cache()
8.4 CJK 特殊处理
BaseRecogn(videotrans/recognition/_base.py:58-80)在 __post_init__ 中对中日韩等语言进行特殊处理:
join_word_flag:CJK 语言(zh, ja, ko, yu, th, km, yue)字幕词间不加空格(其他语言加空格)maxlen:CJK 语言每行最大字符数为settings.cjk_len(默认 15),其他语言为settings.other_len(默认 40)jianfan:中文语言且settings.zh_hant_s=True时启用繁简转换
8.5 翻译调度策略
BaseTrans.run() 根据 aisendsrt 标志选择不同策略:
| 模式 | 条件 | 方法 | 并发数 |
|---|---|---|---|
| 逐行翻译 | 非 AI 渠道 | _run_text() → _item_task() | settings.trans_thread(默认 10) |
| 全文翻译 | AI 渠道 + aisendsrt=True | _run_srt() | settings.aitrans_thread(默认 50) |
8.6 TTS 调度策略
BaseTTS.run() 根据渠道类型选择执行方式:
| 渠道类型 | 调度方式 | 说明 |
|---|---|---|
| Edge-TTS | asyncio 异步 | 单线程内 async 并发 |
| 其他渠道 | ThreadPoolExecutor | 由 dubbing_thread 控制并发数(默认 1) |
渠道子类可重写 _exec() 方法实现自定义调度。BaseTTS 默认调用 __local_mul_thread() → _item_task()。
九、交互式单视频处理模式
当用户选择 1 个视频 且在**标准模式(biaozhun)**下时,程序采用不同于批量流水线的处理模型。
9.1 实现:Worker(QThread)
videotrans/task/only_one.py(148 行)中的 Worker 类在单个 QThread 内串行执行全部 9 个阶段,通过 uito = Signal(str, SignMsg) 与主线程通信:
Worker.run()
├── trk = TransCreate(cfg=TaskCfgVTT(**self.cfg | obj))
├── trk.prepare()
├── trk.recogn()
├── trk.diariz()
├── [暂停点 ①] → _post(type='edit_subtitle_source')
│ 用户校对原始字幕 → 点击"确定"或等待倒计时
├── trk.trans() (if should_trans)
├── [暂停点 ②] → _post(type='edit_subtitle_target')
│ 用户校对翻译字幕 + 分配说话人角色 → 点击"确定"
├── trk.dubbing() (if should_dubbing)
├── [暂停点 ③] → _post(type='edit_dubbing')
│ 用户修改配音结果 → 点击"确定"
├── trk.align()
├── trk.recogn2pass()
├── trk.assembling()
└── trk.task_done()9.2 与批量模式的关键差异
| 维度 | 单视频模式 | 批量模式 |
|---|---|---|
| 执行线程 | Worker(QThread) 直接执行,不使用队列管道 | TransCreate 推入 prepare_queue,经 9 个 Worker 队列流动 |
| 消息通道 | uito 信号直接连接到 WinAction.update_data() | BaseCon.signal() → push_queue() → SignalHub |
| 暂停机制 | 三段暂停点,用户可中间编辑 | 不支持暂停编辑 |
| 进度显示 | 字幕编辑区实时显示 | 进度条 + 按钮文本 |
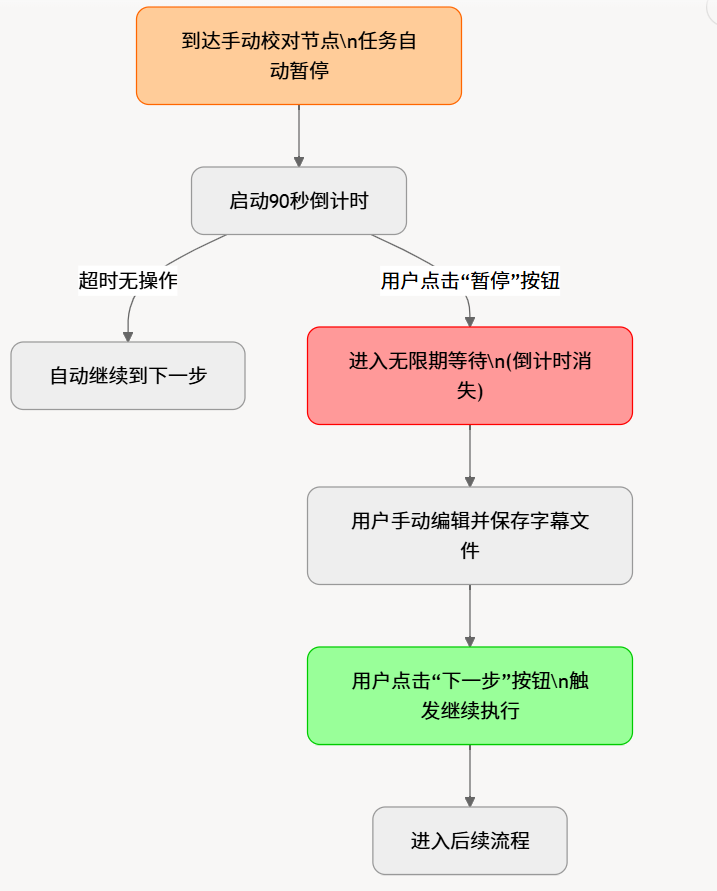
9.3 倒计时与暂停机制
- 自动倒计时:
app_cfg.set_countdown(86400)设置初始值。Worker 线程每sleep(1)递减一次。默认倒计时由settings.countdown_sec控制。 - 无限期暂停:用户点击"停止"按钮将
app_cfg.current_status设为'stop',Worker 的_exit()检测后退出;或set_countdown(-1)让倒计时消失。 - 手动继续:用户在校对对话框中点击"确定"后,
WinAction.set_djs_timeout()调用app_cfg.set_countdown(-1)使倒计时立即归零。
9.4 校对对话框
| 对话框 | 文件 | 功能 |
|---|---|---|
EditRecognResultDialog | component/onlyone_set_recogn.py | 原始字幕编辑(文本 + 时间轴) |
SpeakerAssignmentDialog | component/onlyone_set_role.py | 翻译字幕编辑 + 逐行分配配音角色 |
EditDubbingResultDialog | component/onlyone_set_editdubb.py | 配音结果试听 + 单独重新配音 |

十、音画对齐引擎(SpeedRate)
videotrans/task/_rate.py(877 行)实现了 SpeedRate 和 TtsSpeedRate 两个对齐引擎:
10.1 SpeedRate(视频翻译场景)
处理策略(按优先级):
| 条件 | 策略 |
|---|---|
| 启用音频加速 + 视频慢速 | 各负担一半时间差(忽略倍率限制) |
| 仅启用音频加速 | 加速配音到匹配字幕时长(最高不超过 max_audio_speed_rate) |
| 仅启用视频慢速 | 慢放视频片段到匹配配音时长(最高不超过 max_video_pts_rate) |
| 两者均未启用 | 按字幕时间轴拼接音频片段,填充静音/定格处理时长差异 |
额外处理:
remove_silent_mid:去除字幕之间的静音区间align_sub_audio:强制对齐字幕时间轴到实际配音位置- 末尾静音移除
10.2 TtsSpeedRate(纯配音场景)
简化版对齐引擎,仅负责音频拼接与加速,无视频慢放逻辑。
十一、软件启动与 UI 实现
11.1 启动流程
sp.py 是唯一入口(221 行),启动过程如下:
sp.py (if __name__ == "__main__")
│
├── 1. multiprocessing.freeze_support() / set_start_method('spawn')
├── 2. qInstallMessageHandler() 抑制 Qt 警告
├── 3. atexit.register(cleanup) 注册退出清理
├── 4. QApplication.setHighDpiScaleFactorRoundingPolicy(PassThrough)
├── 5. 创建 QApplication
├── 6. 检测是否在压缩包内运行(PyInstaller 打包版)
├── 7. 创建 StartWindow (splash screen, 无边框半透明)
│ └── QTimer.singleShot(100ms) → initialize_full_app()
│ ├── 重定向 sys.stdout/stderr 到日志文件
│ ├── 设置全局异常钩子 show_global_error_dialog
│ ├── 解析 --lang CLI 参数
│ ├── 导入 darkstyle_rc(编译后的 QRC 资源)
│ ├── 加载 QSS 样式表 (videotrans/styles/style.qss)
│ ├── 恢复上次窗口大小 (QSettings)
│ └── 实例化 MainWindow → uito 连接 splash.update_lable
│ └── MainWindow.__init__()
│ ├── setupUi() → 填充下拉列表(翻译/识别/TTS 渠道、语言列表)
│ ├── AiLoaderThread 启动 → 检测 GPU → 回调 _start_workers()
│ ├── _start_workers() → start_thread() 启动 9 种 Worker 线程
│ ├── _set_default() → 恢复上次用户选择
│ ├── _bind_signal() → 绑定 ~60 个控件事件
│ ├── SignalHub.new_message.connect(win_action.update_data)
│ └── uito.emit('end') → splash 关闭
└── 8. app.exec() → Qt 事件循环11.2 退出机制
用户点击关闭按钮时:
- 设置
app_cfg.exit_soft = True,app_cfg.current_status = 'stop' - 主窗口立即隐藏(
hide()) - 保存窗口尺寸到
QSettings - 隐藏/关闭所有子窗口
- 等待 ~4 秒让所有 Worker 完成当前工作并安全退出
- 清理临时目录
TEMP_ROOT atexitcleanup 回调执行 → 程序终止- 若为重启模式,启动新进程后
os._exit(0)
11.3 UI 架构分层
UI 定义层 videotrans/ui/ ← PySide6 UI 布局文件(~75 个),dark/ 资源文件
↓
UI 逻辑层 videotrans/component/ ← 通用组件:进度条、设置表单、字幕编辑器、实时语音识别、视频裁剪、文本比对
↓
窗口管理层 videotrans/winform/ ← 懒加载的 ~65 个设置/功能窗口模块
↓
主窗口层 videotrans/mainwin/
├── main_win.py ← MainWindow(QMainWindow): UI 初始化、信号绑定、Worker 启动、窗口生命周期(528 行)
├── _actions.py ← WinAction: 核心业务逻辑 → 参数收集 → 任务启动 → 状态分发(798 行)
└── _actions_base.py ← WinActionBase: 代理管理、模式切换、文件选择、CUDA 检测、试听(590 行)
↓
任务层 videotrans/task/ ← TransCreate、SpeechToText、DubbingSrt、TranslateSrt、Worker 线程、SpeedRate11.4 MainWindow——主窗口
videotrans/mainwin/main_win.py(528 行)职责:
setupUi():加载 UI 布局,填充下拉列表(翻译渠道、识别渠道、TTS 渠道、语言、字幕类型)_bind_signal():绑定约 60 个控件事件到WinAction方法_start_workers(status):GPU 检测完成后启动 9 种 Worker 后台线程open_winform(name):统一窗口打开入口(优先复用已缓存的app_cfg.child_forms,否则调用winform.get_win(name).openwin())closeEvent():安全关闭流程(标记退出 → 隐藏窗口 → 停止线程 → 清理临时文件)restart_app():询问确认后触发closeEvent()并启动新进程
11.5 WinAction——核心控制器
WinAction 继承自 WinActionBase(两者均为 @dataclass),是连接 UI 和后台任务的关键枢纽:
WinActionBase(mainwin/_actions_base.py,590 行)提供:
- 文件选择(
get_mp4())—— 单文件/文件夹模式 - 输出目录设置(
get_save_dir()) - 代理配置(
change_proxy(),check_proxy(),proxy_alert()) - 模式切换(
set_biaozhun(),set_tiquzimu())—— 控制 UI 元素显隐 - CUDA 检测(
check_cuda(),cuda_isok()) - 试听功能(
listen_voice_fun())—— 创建ListenVoice线程 - 角色列表更新(
tts_type_change(),set_voice_role()) - 高级选项折叠(
toggle_adv()) - UI 启用/禁用控制(
disabled_widget(),_disabled_button())
WinAction(mainwin/_actions.py,798 行)提供:
check_start():收集所有 UI 控件值 → 构建cfg字典 → 参数校验 → 调用create_btns()create_btns():格式化输入文件路径 → 创建进度条 → 单视频启动Worker,批量启动MultVideoupdate_data(uuid, SignMsg):连接SignalHub.new_message信号 → 按消息类型分发update_status(type):切换ing/stop/end状态,控制按钮和进度条set_process_btn_text(d):更新进度条文本/百分比/颜色retry():重新处理失败的任务_check_all_done():检测是否所有任务完成
十二、异常体系
videotrans/configure/excepts.py(376 行)定义了分层异常:
VideoTransError (基类)
├── TranslateSrtError # 翻译相关错误
├── DubbingSrtError # 配音相关错误
├── SpeechToTextError # 语音识别相关错误
├── LLMSegmentError # LLM 重新断句错误
├── FFmpegError # FFmpeg 操作错误
├── DownloadModelsError # 模型下载错误
├── SttTimeoutError # STT 子进程超时
├── StopTask # 需立即停止的任务异常
└── StopRetry # 不可重试的错误get_msg_from_except(e) 函数映射数十种第三方库异常为用户可读的中/英文错误消息(覆盖 httpx、openai、requests、deepgram、elevenlabs、tenacity 等)。
NO_RETRY_EXCEPT 元组定义了不可恢复的异常类型,翻译/配音模块在重试循环中遇到这些异常时直接放弃。
十三、代码结构概览
/
├── sp.py # ★ 主程序入口(221 行)
├── cli.py # ★ CLI 命令行入口
├── models/ # 存放本地 AI 模型文件(ONNX 等)
├── logs/ # 日志文件目录(YYYYMMDD.log)
├── ffmpeg/ # ffmpeg 及 sox 二进制文件
├── f5-tts/ # 声音克隆参考音频存放目录
├── docs/ # 文档
├── tmp/ # 临时文件根目录
│ ├── _temp/ # 进程级临时目录
│ └── translate_cache/ # 翻译 MD5 缓存目录
│
└── videotrans/ # 核心业务逻辑代码
│ __init__.py # ★ VERSION, ChannelProvider 定义, get_class() 懒加载
│ cfg.json # settings 持久化文件
│ params.json # params 持久化文件
│ codec.json # 视频编解码器缓存
│
├── codes/
│ └── model.py # 模型相关定义
│
├── configure/ # 全局配置、队列定义、顶层基类
│ ├── config.py # ★ AppCfg / AppSettings / AppParams / logger / 队列定义 / tr() / push_queue()(902 行)
│ ├── base.py # ★ BaseCon 基类(_new_process, signal, _exit, convert_to_wav 等)(296 行)
│ ├── contants.py # ★ 全局常量(模型列表、语言测试文本、标点符号、代理白名单等)
│ ├── excepts.py # ★ 异常体系 + get_msg_from_except()(376 行)
│ ├── signal_hub.py # ★ SignalHub 单例(跨线程 Qt 信号)(33 行)
│ └── whispernet_config.py # Whisper.NET 配置
│
├── task/ # 任务处理逻辑与后台线程
│ ├── _base.py # ★ BaseTask 基类(8 阶段空方法 + 5 标志位 + 共享工具方法)(167 行)
│ ├── taskcfg.py # ★ TaskCfgBase/VTT/STT/TTS/STS + InputFile + SignMsg + SrtItem(261 行)
│ ├── trans_create.py # ★ TransCreate 完整实现(~1678 行,视频翻译核心)
│ ├── speech2text.py # ★ SpeechToText(批量语音转字幕)
│ ├── dubbing.py # ★ DubbingSrt(批量字幕配音)
│ ├── translate_srt.py # ★ TranslateSrt(批量翻译 SRT 字幕)
│ ├── job.py # ★ 9 种 BaseWorker 子类 + start_thread() 入口(245 行)
│ ├── only_one.py # ★ 单视频交互式 Worker(QThread) + uito 信号(148 行)
│ ├── mult_video.py # ★ 多视频批量提交 MultVideo(QThread)(54 行)
│ ├── _rate.py # SpeedRate / TtsSpeedRate 音画对齐引擎(877 行)
│ ├── separate_worker.py # SeparateWorker 独立人声分离 QThread
│ ├── simple_runnable_qt.py # QRunnable 线程池工具
│ ├── child_win_sign.py # 子窗口信号处理
│ └── update_ffmpeg.py # ffmpeg 更新管理
│
├── recognition/ # 语音识别 (ASR) 模块(22 个渠道)
│ ├── __init__.py # ★ 渠道常量 ID、_ID_NAME_DICT、run()、is_allow_lang()、is_input_api()
│ ├── _base.py # ★ BaseRecogn(VAD 分割、CJK 处理、字幕合并,400 行)
│ └── _*.py # 22 个渠道实现(_whisper, _whisperx, _whispernet, _qwenasrlocal, _qwen3asr, _funasr 等)
│
├── translator/ # 字幕翻译模块(24 个渠道)
│ ├── __init__.py # ★ 渠道常量、_ID_NAME_DICT、LANG_CODE、run()、is_allow_translate()(860 行)
│ ├── _base.py # ★ BaseTrans(MD5 缓存、逐行/全文翻译调度,176 行)
│ └── _*.py # 24 个渠道实现(_google, _chatgpt, _deepseek, _gemini, _deepl, _baidu 等)
│
├── tts/ # 文本转语音 (TTS) 模块(**34** 个渠道)
│ ├── __init__.py # ★ 渠道常量 ID、_ID_NAME_DICT、SUPPORT_CLONE、CHANGE_BY_LANGUAGE、run()(192 行)
│ ├── _base.py # ★ BaseTTS(异步/多线程并发调度,304 行)
│ └── _*.py # 34 个渠道实现(_edgetts, _openaitts, _azuretts, _gptsovits, _cosyvoice 等)
│
├── process/ # 独立子进程实现
│ ├── __init__.py # 子进程函数导出
│ ├── signelobj.py # ★ GlobalProcessManager(CPU/GPU 双进程池,167 行)
│ ├── prepare_audio.py # 人声分离、降噪、标点恢复、说话人分离(4 种后端)
│ ├── stt_fun.py # ASR 子进程入口(openai_whisper, faster_whisper, paraformer, funasr_mlt, qwen3asr_fun 等)
│ ├── tts_fun.py # TTS 子进程入口(qwen3tts_fun)
│ └── vad.py # VAD 语音活动检测(Silero VAD)
│
├── mainwin/ # 主窗口界面与业务逻辑
│ ├── main_win.py # ★ MainWindow(QMainWindow) 初始化、信号绑定、线程启动(528 行)
│ ├── _actions.py # ★ WinAction 核心控制器(检查、启动、状态更新,798 行)
│ └── _actions_base.py # ★ WinActionBase 基类(代理、模式切换、CUDA、文件选择,590 行)
│
├── component/ # UI 通用组件
│ ├── progressbar.py # 可点击进度条
│ ├── set_form.py # 通用设置表单 / 关于页面
│ ├── onlyone_set_recogn.py # 单视频模式:原始字幕编辑对话框
│ ├── onlyone_set_role.py # 单视频模式:说话人角色分配对话框
│ ├── onlyone_set_editdubb.py # 单视频模式:配音结果编辑对话框
│ ├── clip_video.py # 视频裁剪组件
│ ├── realtime_stt.py # 实时语音识别窗口
│ ├── textmatching.py # 文本比对窗口
│ ├── set_proxy.py # 代理设置弹窗
│ ├── set_ass.py # ASS 字幕样式设置
│ ├── set_cpp.py # Whisper.cpp 路径设置
│ ├── set_xxl.py # Faster-Whisper-XXL 路径设置
│ ├── set_subtitles_length.py # 字幕长度设置
│ ├── set_threads.py # 线程数设置
│ └── controlobj.py # 控件对象管理
│
├── ui/ # PySide6 UI 定义文件(~75 个.py 文件)
│ ├── en.py # ★ 主窗口 UI 布局定义
│ ├── chatgpt.py, deepseek.py, gemini.py, ... # 各渠道设置对话框布局
│ ├── videoandaudio.py, separate.py, peiyin.py, ... # 功能窗口布局
│ └── dark/ # 暗色主题资源(darkstyle_rc.py, palette.py)
│
├── winform/ # 各渠道设置窗口懒加载管理(~65 个模块)
│ ├── __init__.py # ★ get_win() 懒加载入口 + _module_map(91 行)
│ ├── chatgpt.py, azure.py, baidu.py, ... # ~50 个渠道设置窗口(openwin())
│ └── fn_*.py # ~10 个独立功能窗口(批量语音转字幕、批量为字幕配音、批量翻译srt字幕等)
│
├── styles/ # UI 样式与媒体资源
│ ├── style.qss # Qt 样式表
│ ├── logo.png # 启动画面 logo
│ ├── icon.ico # 应用图标
│ ├── simhei.ttf # 黑体中文字体
│ ├── preview.png # 预览图
│ ├── no-remove.mp4 # 防清理的占位视频
│ └── no-remove.wav # 防清理的占位音频
│
├── util/ # 通用工具函数(18 个文件)
│ ├── tools.py # ★ 核心工具函数(ffmpeg 封装、字幕解析/格式化、文件操作、系统通知、模型下载)
│ ├── gpus.py # GPU 检测与分配(get_cudaX 获取可用 GPU 索引)
│ ├── checkgpu.py # GPU 检测线程(AiLoaderThread)
│ ├── ListenVoice.py # 声音试听功能(ListenVioce QThread)
│ ├── req_fac.py # HuggingFace 自定义 session 工厂
│ ├── cn_tn.py # 中文文本规范化
│ ├── en_tn.py # 英文文本规范化
│ ├── help_down.py # 下载工具函数
│ ├── help_ffmpeg.py # ffmpeg 视频编解码器检测
│ ├── help_misc.py # 杂项工具
│ ├── help_role.py # 配音角色工具
│ ├── help_srt.py # 字幕文件工具
│ ├── helper_supertonic.py # Supertonic TTS 辅助
│ ├── TestSrtTrans.py # 翻译测试工具
│ └── TestSTT.py # STT 测试工具
│
├── language/ # 界面多语言 JSON 文件
│ ├── en.json
│ ├── zh.json
│ └── ... # 30+ 语言
│
├── prompts/ # AI 翻译提示词模板(31 个文件)
│ ├── srt/ # SRT 格式翻译 prompt(chatgpt.txt, deepseek.txt 等 13 个)
│ ├── text/ # 纯文本翻译 prompt(同 13 个)
│ ├── recogn/ # 语音识别 prompt(gemini_recogn.txt)
│ └── recharge/ # LLM重新断句 prompt(recharge-llm.txt)
│
└── voicejson/ # TTS 音色配置文件(14 个 JSON)
├── edge_tts.json # Edge-TTS 各语言音色列表
├── azure_voice_list.json # Azure TTS 音色列表
├── qwen3tts.json # Qwen3-TTS 音色
└── ... # 其他渠道音色配置十四、扩展开发指南
14.1 新增一个翻译通道
假设要新增翻译通道 MyTranslator:
Step 1: 创建通道实现文件
在 videotrans/translator/ 下创建 _mytranslator.py:
from dataclasses import dataclass
from videotrans.translator._base import BaseTrans
@dataclass
class MyTranslator(BaseTrans):
def __post_init__(self):
super().__post_init__()
self.api_url = 'https://api.example.com/translate'
def _item_task(self, data: dict) -> str:
text = data['text']
source = data['source_code']
target = data['target_code']
result = call_my_api(text, source, target)
return resultStep 2: 分配渠道 ID 并注册
在 videotrans/translator/__init__.py 中:
MYTRANSLATOR_INDEX = 24 # 分配不重复的整数 ID
# 在 _ID_NAME_DICT 末尾添加:
_ID_NAME_DICT[MYTRANSLATOR_INDEX] = ChannelProvider(
"My Translator",
imp="._mytranslator",
key_name="mytranslator_key",
win="mytranslator"
)Step 3: 添加用户配置字段
在 videotrans/configure/config.py 的 AppParams._get_defaults() 中添加:
"mytranslator_key": "",
"mytranslator_model": "model-v1",Step 4: 创建设置窗口
在 videotrans/winform/ 下创建 mytranslator.py,实现 openwin() 函数。在 videotrans/winform/__init__.py 的 _module_map 中注册:
"mytranslator": ".mytranslator",Step 5: 可选扩展
- 在
is_allow_translate()中添加语言兼容性检测 - 在
ui/目录下新增界面文件 - 在菜单
ui/en.py中添加对应 Action
14.2 新增一个 TTS 通道
步骤与翻译通道类似:
- 创建
videotrans/tts/_mytts.py,继承BaseTTS - 在
videotrans/tts/__init__.py中分配 ID 并注册_ID_NAME_DICT - 如需声音克隆支持,将 ID 加入
SUPPORT_CLONE列表 - 如需语言跟随角色变化,将 ID 加入
CHANGE_BY_LANGUAGE列表 - 在
AppParams._get_defaults()中添加对应的 API Key / URL 配置字段 - 在
videotrans/winform/和_module_map中注册设置窗口
14.3 新增一个识别通道
步骤同翻译/TTS,渠道实现类继承 BaseRecogn,必须实现 .run() 方法返回 List[SrtItem]。
14.4 常规约定
- 所有渠道类使用
@dataclass+__post_init__ - 通过
get_class(channel_id, "recognition/translator/tts", _ID_NAME_DICT)懒加载 - API key 校验依赖
is_input_api()函数 +_ID_NAME_DICT中的key_name/win字段 - 翻译/配音引擎内部并发数由
settings中的对应字段控制
版本: v4.03 (VERSION_NUM=403) 主页: https://github.com/jianchang512/pyvideotrans文档: https://pyvideotrans.comBBS: https://bbs.pyvideotrans.com