批量语音转字幕
支持的视频格式:
mp4 / mov / avi / mkv / webm / mpeg / ogg / mts / ts支持的音频格式:
wav / mp3 / m4a / flac / aac
这是一个专门用于将音频视频文件转录为文字或字幕的功能面板。如果你不想翻译视频,而仅仅想批量根据音视频生成字幕,那么这个功能再合适不过了。
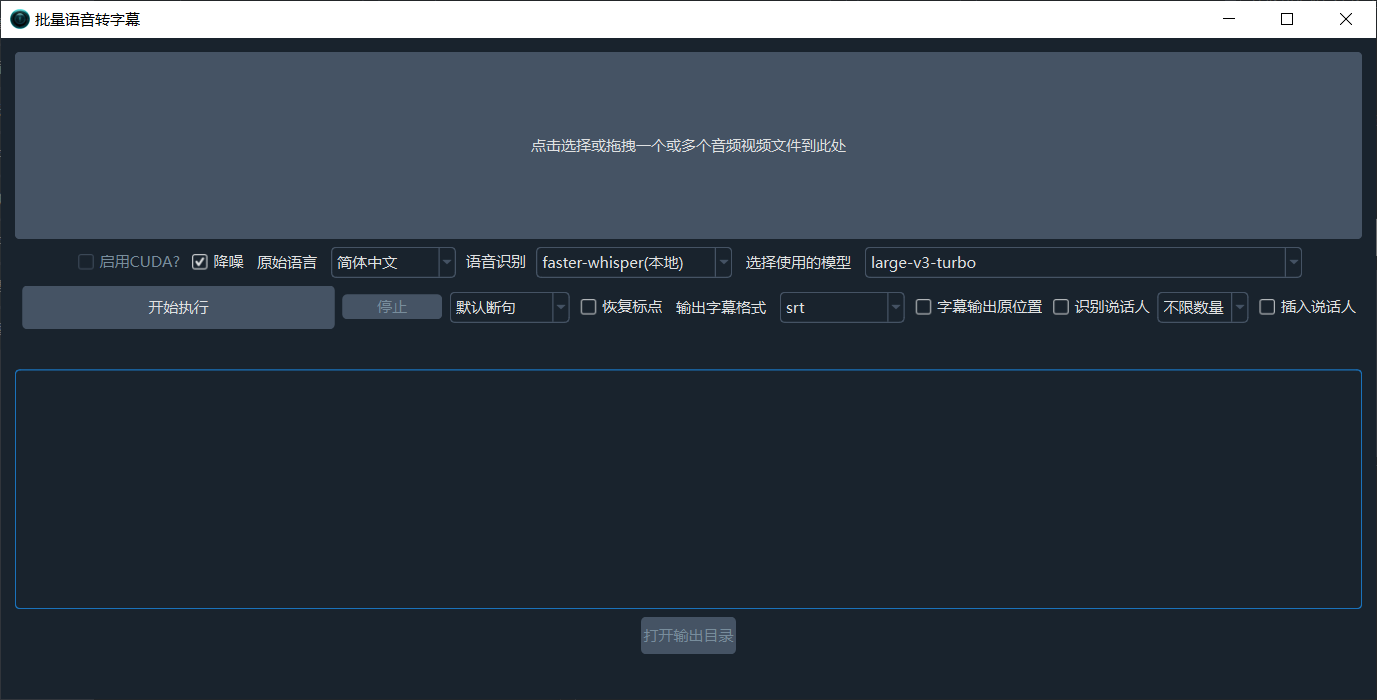
操作流程
- 导入文件:点击顶部大按钮,或直接拖拽文件进去,可支持一个或多个文件
- 设置参数:选择原始语言、识别渠道和模型
- 开始转录:点击开始按钮
主要参数说明
基础设置
| 参数 | 说明 |
|---|---|
| 启用 CUDA | Windows/Linux 系统如果有 NVIDIA 显卡并配置了 CUDA,可选中以加快转录速度 |
| 原始语言 | 音视频中说话的语言,请正确选择。如果不确定,可下拉选择「auto」自动检测 |
语音识别渠道
| 渠道 | 说明 | 推荐场景 |
|---|---|---|
| faster-whisper(本地) | 本地模型,速度和质量都较好,支持数十种语言 | 默认推荐 |
| openai-whisper(本地) | 准确度略高,速度较慢 | 高精度需求 |
| Qwen-ASR(本地) | 中文效果极佳 | 中文视频 |
| 阿里 FunASR(本地) | 中文优化模型 | 中文视频 |
| Huggingface_ASR(本地) | 支持多种语言模型 | 多语言场景 |
| 字节火山字幕生成 | 在线 API | 中文视频 |
| OpenAI 语音识别 | 在线 API | 英语等语言 |
| Gemini 语音识别 | 在线 API | 小语种支持 |
| 阿里 Qwen3-ASR | 在线 API | 中文视频 |
模型选择
模型越大越准确,但速度越慢、消耗资源越多:
| 模型 | 速度 | 准确度 | 显存需求 |
|---|---|---|---|
| tiny | 最快 | 低 | ~1GB |
| base / small | 中 | 中 | ~1-2GB |
| medium | 较慢 | 较高 | ~5GB |
| large-v3 | 慢 | 最高 | ~8GB |
| large-v3-turbo | 较快 | 高 | ~6GB |
高级功能
| 功能 | 说明 |
|---|---|
| 降噪 | 选中后,在语音识别之前先消除背景噪声,提升识别准确度 |
| 识别说话人 | 选中后,识别结束后尝试区分不同说话人(后方数字设定预估说话人数) |
| 插入说话人 | 选中后,在字幕文本开头插入说话人标识,如 [spk0] |
| 默认断句 / LLM 重新断句 | 可选择默认断句,或使用大语言模型对识别结果进行智能断句和标点优化 |
| 输出格式 | 默认以 SRT 字幕格式输出,可选 TXT、VTT、ASS |
| 整体识别 vs 批量推理 | 整体识别使用内置 VAD 检测语音,断句效果更佳;批量推理速度更快但断句略差 |
| 字幕输出原位置 | 选中后将转录结果放在原始音视频同文件夹内 |
字幕多角色配音
支持为每行字幕单独指定一个发音人,实现多角色配音。
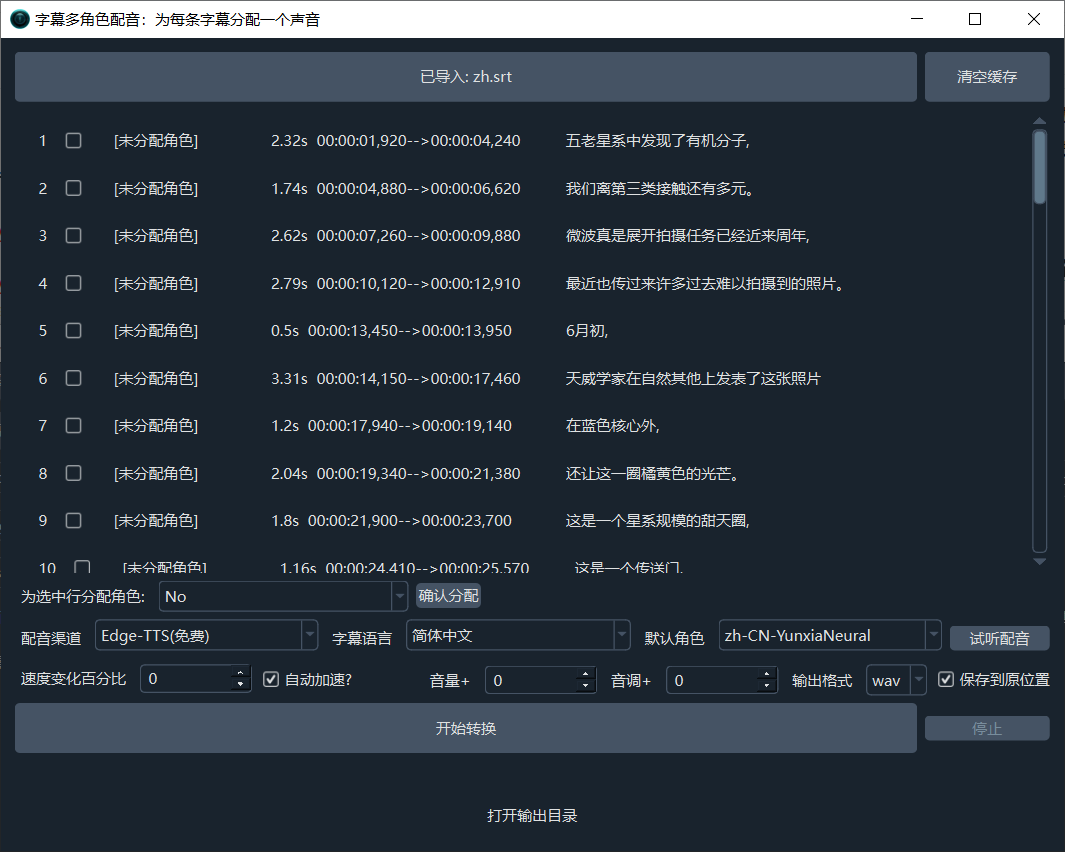
支持配音的字幕格式:
srt。更多详情请参考 原声克隆与多角色配音。
常见问题
Q: 转录结果为空或乱码?
- 检查「原始语言」是否选择正确
- 检查视频是否有声音(某些在线视频画面和声音是分开下载的)
- 尝试开启降噪功能
- 更换识别渠道或模型
Q: 转录速度太慢?
- 启用 CUDA 加速(需要 NVIDIA 显卡)
- 使用较小的模型(如
base) - 将「最长语音持续秒数」设大一些,减少分割次数
Q: 如何提高中文识别效果?
推荐使用 Qwen-ASR 或阿里 FunASR,这两个模型对中文优化效果最好。