Qwen-ASR 本地语音识别模型
这是什么?
Qwen-ASR 是由阿里巴巴通义千问团队开发的本地语音识别模型,能够在不联网的情况下将音频中的语音内容转换为文字。该模型完全在本地运行,保护隐私的同时提供高精度的语音识别能力。
在 pyVideoTrans 的语音识别渠道中选择 Qwen-ASR(本地) 即可使用此模型。
版本要求
必须升级到 v3.97+ 版本才能使用 Qwen-ASR 本地模型
模型选择
Qwen-ASR 提供两种尺寸的模型,各有优劣:
| 模型 | 参数量 | 识别准确率 | 资源消耗 | 推荐场景 |
|---|---|---|---|---|
| 0.6B | 6亿参数 | 较高 | 较低 | 显存有限、追求速度 |
| 1.7B | 17亿参数 | 更高 | 较高 | 追求准确率、显存充足 |
- 0.6B 模型:体积较小,推理速度快,对显存要求较低,适合配置一般的电脑
- 1.7B 模型:识别准确率更高,但需要更多显存和计算资源,适合追求最佳效果的用户
模型下载
自动下载(推荐)
首次使用时,软件会自动从模型仓库下载所需模型,无需手动操作。中文界面默认使用 ModelScope(魔搭)国内镜像下载。
手动下载
如果自动下载失败或速度较慢,可以手动下载模型。
步骤一:确认目录结构
在软件目录下确认存在以下模型文件夹,如不存在请手动创建:
软件目录/
└── models/
├── models--Qwen--Qwen3-ASR-0.6B/ (0.6B模型目录)
└── models--Qwen--Qwen3-ASR-1.7B/ (1.7B模型目录)步骤二:下载 1.7B 模型
- 打开 HuggingFace 下载页面:https://huggingface.co/Qwen/Qwen3-ASR-1.7B/tree/main
- 将页面中所有文件下载下来
- 将下载的文件全部放入
models/models--Qwen--Qwen3-ASR-1.7B文件夹内
步骤三:下载 0.6B 模型
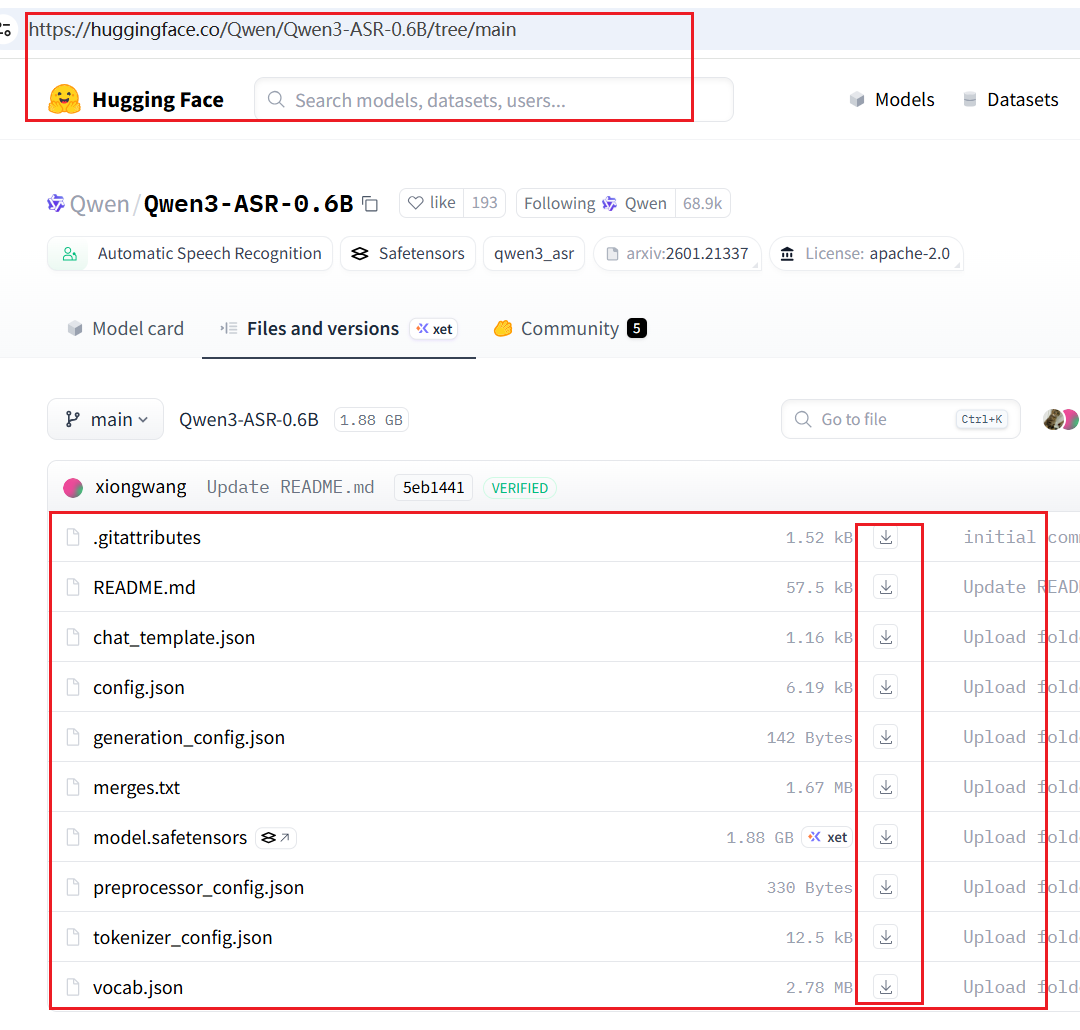
- 打开 HuggingFace 下载页面:https://huggingface.co/Qwen/Qwen3-ASR-0.6B/tree/main
- 将页面中所有文件下载下来
- 将下载的文件全部放入
models/models--Qwen--Qwen3-ASR-0.6B文件夹内
步骤四:选择模型
在软件界面的语音识别设置中,根据需要选择 0.6B 或 1.7B 模型。
工作原理
Qwen-ASR 本地模型采用 VAD(语音活动检测) 技术进行音频预处理:
- 使用
ten-vad模型对音频进行智能裁切,分割为多个短音频片段 - 将裁切后的片段按照每 8 个为一批进行批量推理
- 最终合并所有片段的识别结果
这种方式的优势是显存占用低、推理速度快,适合处理长音频文件。
高级配置:使用 ForcedAligner 对齐
什么是 ForcedAligner
Qwen 官方提供 Qwen/Qwen3-ForcedAligner-0.6B 模型用于精确的时间轴对齐。与默认的 VAD 方式不同,ForcedAligner 能直接处理完整长音频,提供更精确的字级时间戳。
为什么默认不启用
- 显存消耗非常大
- 推理速度较慢
- 无法展示实时转录进度,长音频处理时界面会长时间无响应
手动启用 ForcedAligner
如果你对断句精度有更高要求,可以通过以下步骤手动启用 ForcedAligner:
前置条件:需要以源码方式部署 pyVideoTrans
第一步:修改 stt_fun.py
打开 videotrans/process/stt_fun.py 文件,进行以下修改:
- 将原函数
qwen3asr_fun重命名为qwen3asr_fun_bak:
# 修改前
def qwen3asr_fun(
cut_audio_list=None,
ROOT_DIR=None,
logs_file=None,
defaulelang="en",
is_cuda=False,
audio_file=None,
TEMP_ROOT=None,
model_name="1.7B",
device_index=0
):
...
# 修改后
def qwen3asr_fun_bak(
cut_audio_list=None,
ROOT_DIR=None,
logs_file=None,
defaulelang="en",
is_cuda=False,
audio_file=None,
TEMP_ROOT=None,
model_name="1.7B",
device_index=0
):
...- 将原函数
qwen3asr_fun0重命名为qwen3asr_fun:
# 修改前
def qwen3asr_fun0(
ROOT_DIR=None,
logs_file=None,
defaulelang="en",
is_cuda=False,
audio_file=None,
TEMP_ROOT=None,
model_name="1.7B",
device_index=0
):
...
# 修改后
def qwen3asr_fun(
ROOT_DIR=None,
logs_file=None,
defaulelang="en",
is_cuda=False,
audio_file=None,
TEMP_ROOT=None,
model_name="1.7B",
device_index=0
):
...第二步:修改 _qwenasrlocal.py
打开 videotrans/recognition/_qwenasrlocal.py 文件:
- 取消以下两行代码前的
#注释符号,以便自动下载对齐模型:
# 取消注释 ModelScope 下载(中文环境推荐)
tools.check_and_down_ms('Qwen/Qwen3-ForcedAligner-0.6B',callback=self._process_callback,local_dir=f'{config.ROOT_DIR}/models/models--Qwen--Qwen3-ForcedAligner-0.6B')
# 或取消注释 HuggingFace 下载
tools.check_and_down_hf(model_id='Qwen3-ForcedAligner-0.6B',repo_id='Qwen/Qwen3-ForcedAligner-0.6B',local_dir=f'{config.ROOT_DIR}/models/models--Qwen--Qwen3-ForcedAligner-0.6B',callback=self._process_callback)手动下载方式:也可以手动下载 ForcedAligner 模型,地址为 https://huggingface.co/Qwen/Qwen3-ForcedAligner-0.6B/tree/main,将所有文件放入
models/models--Qwen--Qwen3-ForcedAligner-0.6B文件夹内。
- 同一文件中,将代码:
return jsdata#self.segmentation_asr_data(jsdata)修改为:
return self.segmentation_asr_data(jsdata)第三步:重启软件
所有修改完成后,重新启动 pyVideoTrans 即可。
常见问题
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
| 模型下载失败 | 网络问题或 HuggingFace 被屏蔽 | 使用 ModelScope 镜像下载,或手动下载模型文件 |
| 识别结果为空 | 音频格式不支持 | 确保音频为常见格式(wav/mp3/aac),建议先转为 wav |
| 显存不足报错 | 显卡显存不够 | 使用 0.6B 小模型,或关闭其他占用显存的程序 |
| 识别速度很慢 | 没有使用 GPU 加速 | 检查 CUDA 环境是否正确配置 |
| 软件界面卡死 | 长音频处理时间过长 | 这是正常现象,耐心等待;或使用较短的音频片段 |