语音识别渠道:Faster-Whisper-XXL
这是什么
Faster-Whisper-XXL 是 Purfview/whisper-standalone-win 项目提供的独立可执行文件(faster-whisper-xxl.exe),它将 faster-whisper 语音识别引擎打包为一个单独的 exe 文件,无需安装 Python 环境即可使用。
pyVideoTrans 已内置集成此工具,选择该渠道后可直接调用 faster-whisper-xxl.exe 进行语音识别。
适用场景
- 不想安装 Python 环境,希望开箱即用的用户
- 已经下载了
faster-whisper-xxl.exe,想在 pyVideoTrans 中直接使用的用户 - 需要离线识别且追求高准确率的用户
- 拥有 NVIDIA 显卡可获得最佳性能
前置条件
| 条件 | 说明 |
|---|---|
| faster-whisper-xxl.exe | 需要从 GitHub 下载 |
| NVIDIA 显卡(推荐) | 支持 CUDA 加速,速度提升显著;无显卡可用 CPU 模式 |
| FFmpeg(可选) | 部分音频格式可能需要 |
下载地址
从以下地址下载 faster-whisper-xxl.exe:
https://github.com/Purfview/whisper-standalone-win/releases
下载后解压到任意文件夹(路径中不要包含中文或空格)。
在 pyVideoTrans 中使用
配置步骤
- 下载并解压
faster-whisper-xxl.exe - 打开
pyVideoTrans软件 - 在语音识别渠道中选择 faster-whisper-xxl.exe
- 在弹出的选择框中找到
faster-whisper-xxl.exe的位置 - 选择后即可开始使用
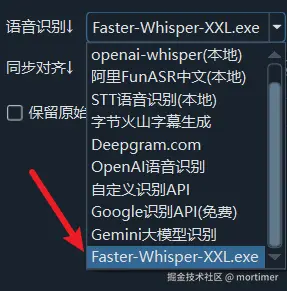
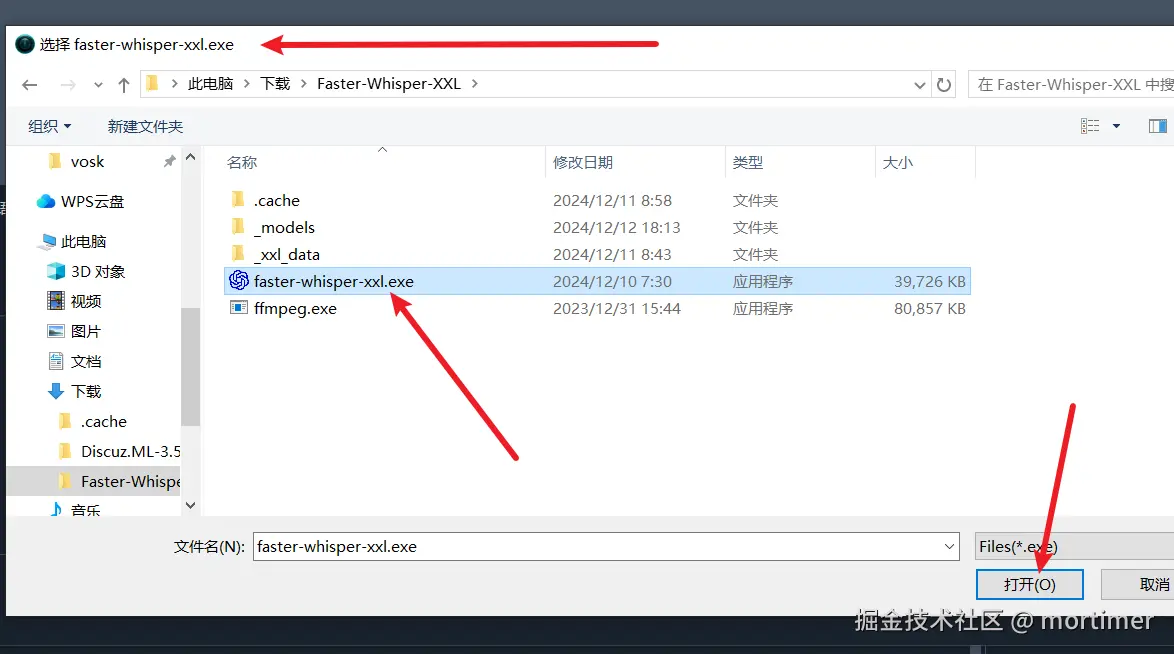
参数说明
pyVideoTrans 在调用 faster-whisper-xxl.exe 时,自动传递以下参数:
| 参数 | 说明 |
|---|---|
| 音频文件路径 | 要识别的音频文件 |
-pp | Pretty Print,格式化输出 |
-f srt | 输出格式为 SRT 字幕 |
-ct | 计算类型(默认 int8,可在设置中修改) |
-l | 识别语言代码 |
--model | 使用的模型名称 |
--output_dir | 输出目录(缓存文件夹) |
--initial_prompt | 初始提示词(可选,用于提高特定领域识别率) |
自定义额外参数
小技巧:
faster-whisper-xxl.exe支持非常多的参数。为了保持灵活性,软件仅内置了模型、语言和输出格式这几个必选参数。你可以通过在faster-whisper-xxl.exe的同目录下创建一个名为pyvideotrans.txt的文件,并在文件中添加其他参数。文件格式应遵循xxl.exe的要求。注意:不要重复添加模型尺寸、语言和输出格式这几个参数,否则会导致错误。
例如,在 faster-whisper-xxl.exe 同目录下创建 pyvideotrans.txt:
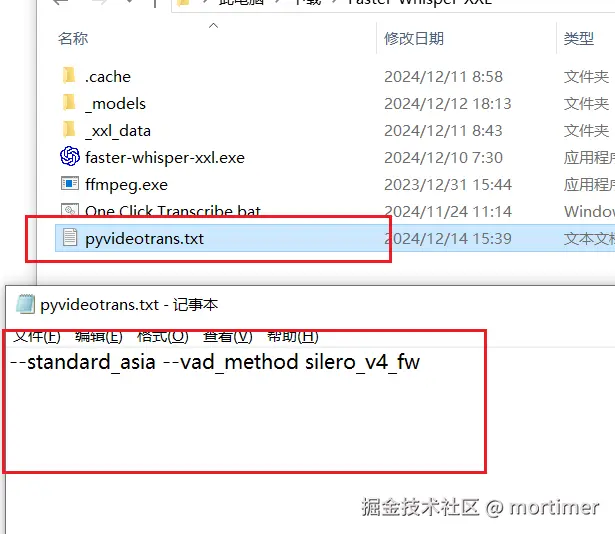
文件内容为需要添加的额外参数,用空格分隔。
最佳配置建议
| 配置项 | 推荐值 | 说明 |
|---|---|---|
| 模型 | large-v3 或 large-v3-turbo | 准确率最高,适合大多数场景 |
| 计算类型(ct) | int8 | 速度和准确率的平衡点;有显卡可用 float16 |
| 语言 | 指定语言 | 比自动检测更准确 |
| 初始提示词 | 领域相关术语 | 可提高专业词汇识别准确率 |
| 计算设备 | GPU(CUDA) | 有 NVIDIA 显卡时强烈推荐 |
常见问题
Q:选择 exe 后提示找不到文件?
A:请确保路径正确,路径中不要包含中文或空格。建议将 exe 放在纯英文路径下。
Q:识别速度很慢?
A:
- 检查是否使用了 GPU 模式(需要 NVIDIA 显卡和 CUDA 支持)
- 尝试切换计算类型为
int8(速度更快) - 使用较小的模型(如
base或small)换取更快的速度
Q:识别结果不准确?
A:
- 尝试使用更大的模型(如
large-v3) - 设置正确的语言参数
- 添加初始提示词,包含音频中的专业术语或人名
Q:pyvideotrans.txt 中的参数不生效?
A:请确认文件放在 faster-whisper-xxl.exe 的同一目录下,而不是 pyVideoTrans 的安装目录。参数之间用空格分隔。
Q:如何查看支持哪些模型?
A:访问 https://github.com/Purfview/whisper-standalone-win/releases 查看项目说明,支持的模型与 faster-whisper 相同。