更好地使用本地大模型作为翻译渠道
DeepSeek、Qwen 等开源 AI 大模型表现出色,借助 Ollama 和 LM Studio 等工具,我们可以在本地轻松搭建大模型服务,并将其集成到视频翻译软件中。
然而,受限于个人电脑的显存,本地部署的大模型通常较小(1.5B、7B、14B、32B 等),而 DeepSeek 官方在线 AI 服务使用的 r1 模型参数量高达 671B。这种巨大的差异意味着本地模型的智能程度相对有限,无法像使用在线模型那样随意使用,否则可能遇到各种问题:翻译结果中出现提示词、原文与译文混杂、甚至出现乱码等。
根本原因在于小模型智能不足,对复杂提示词的理解和执行能力较弱。因此,在使用本地大模型进行视频翻译时,需要注意以下几点:
一、正确配置 API 设置
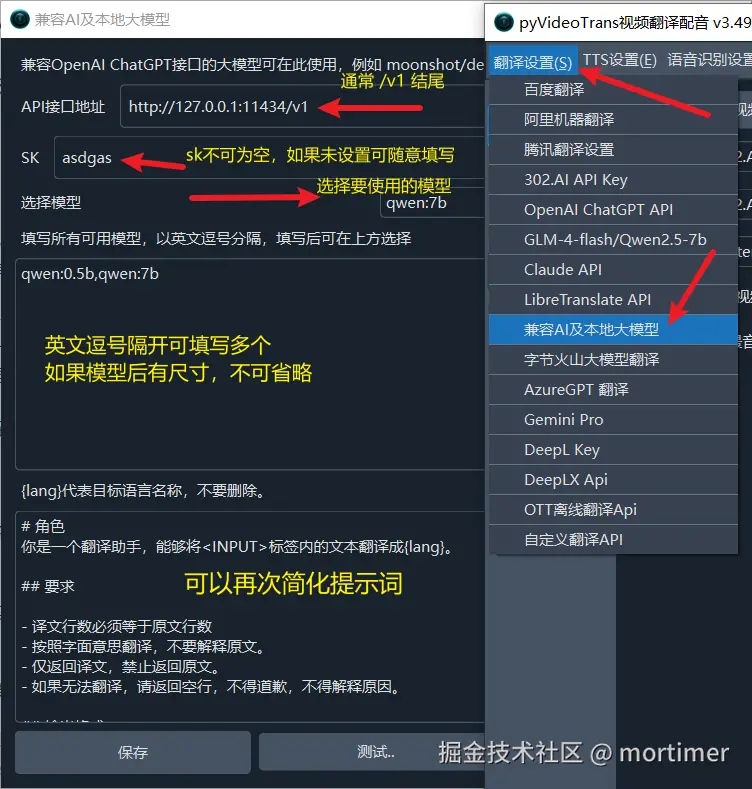
将本地部署模型的 API 地址填写到视频翻译软件 翻译设置 → 兼容 AI 及本地大模型 下的 API 接口地址 中。通常,API 接口地址应以 /v1 结尾。
- 如果你的 API 接口设置了 API Key,请将其填写到 SK 文本框中。如果未设置,则随意填写一个值即可(例如
1234),但不要留空。 - 将模型名称填写到「填写所有可用模型」文本框中。注意:某些模型名称后可能带有尺寸信息(例如
deepseek-r1:8b),末尾的:8b也需要一并填写。
二、优先选择参数量更大、更新的模型
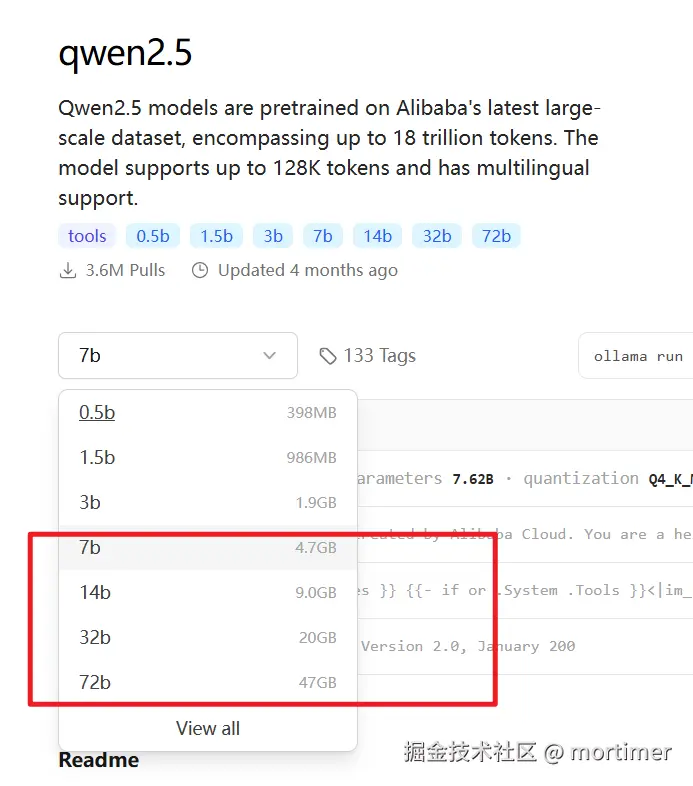
- 建议选择参数量至少为 7B 的模型。如果条件允许,尽量选择大于 14B 的模型。模型越大效果越好。
- 如果使用通义千问系列模型,优先选择 qwen2.5 系列或更新版本,而不是 1.5 或 2.0 系列。
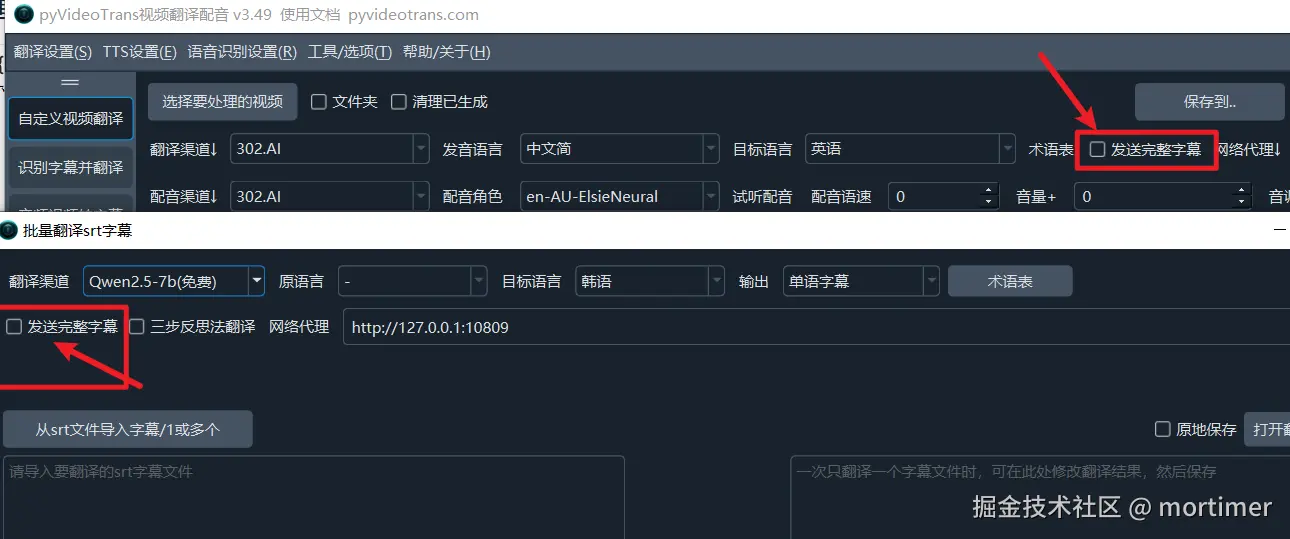
三、取消勾选「发送完整字幕」
除非你部署的模型尺寸大于等于 70B,否则勾选「发送完整字幕」可能会导致字幕翻译结果出错。小模型的上下文窗口有限,一次性发送过多内容会导致理解混乱。
四、合理设置字幕行数参数
将视频翻译软件中的「传统翻译字幕行数」和「AI 翻译字幕行数」都设置为较小的值(例如 1、5 或 10)。这样可以避免出现过多空白行的问题,并提高翻译的可靠性。
值越小,翻译出错的可能性越低,但翻译质量也会下降;值越大,虽然在不出错的情况下翻译质量更好,但也更容易出错。
五、简化提示词 (Prompt)
当模型较小时,可能无法理解或指令遵从性较差。此时,可以简化提示词,使其简单明了。
默认的提示词位于 软件目录/videotrans/prompts/text/localllm.txt(按行翻译模式)或 软件目录/videotrans/prompts/srt/localllm.txt(完整字幕模式)。当发现翻译结果不尽如人意时,可以尝试简化。
简化示例一
# 角色
你是一个翻译助手,能够将<INPUT>标签内的文本翻译成{lang}。
## 要求
- 译文行数必须等于原文行数
- 按照字面意思翻译,不要解释原文。
- 仅返回译文,禁止返回原文。
- 如果无法翻译,请返回空行,不得道歉,不得解释原因。
## 输出格式:
直接输出译文,禁止输出任何其他提示,例如解释、引导字符等。
<INPUT></INPUT>
翻译结果:简化示例二
你是一个翻译助手,将以下文本翻译成{lang},保持行数不变,只返回译文,无法翻译则返回空行。
待翻译文本:
<INPUT></INPUT>
翻译结果:简化示例三
将以下文本翻译为{lang},保持行数一致。如果无法翻译,留空。
<INPUT></INPUT>
翻译结果:你还可以根据实际情况进一步简化和优化提示词。
提醒:花括号中的变量(如
{lang})是程序自动替换的占位符,修改提示词时请保留这些变量,不要删除。
相关文档
- 提高 AI 翻译字幕的质量 — 翻译模式对比与术语表使用
- 更好的使用本地大模型作为翻译渠道 — 本地大模型配置指南
- 修改 AI 翻译提示词 — 自定义翻译提示词
- 视频翻译最佳效果推荐 — 每个阶段的最优配置
- 翻译后出现"空白字幕行"的原因与解决方法