批量为字幕配音 / 语音合成
支持配音的字幕或文本格式:
srt / txt
如果你有很多字幕文件或 txt 文件,想批量为他们创建配音,那么可选择该功能。
将您的 SRT 文件或纯文本,通过选择的 TTS 引擎,批量合成为配音文件(如 WAV 或 MP3)。支持精细调整语速、音量和音调。
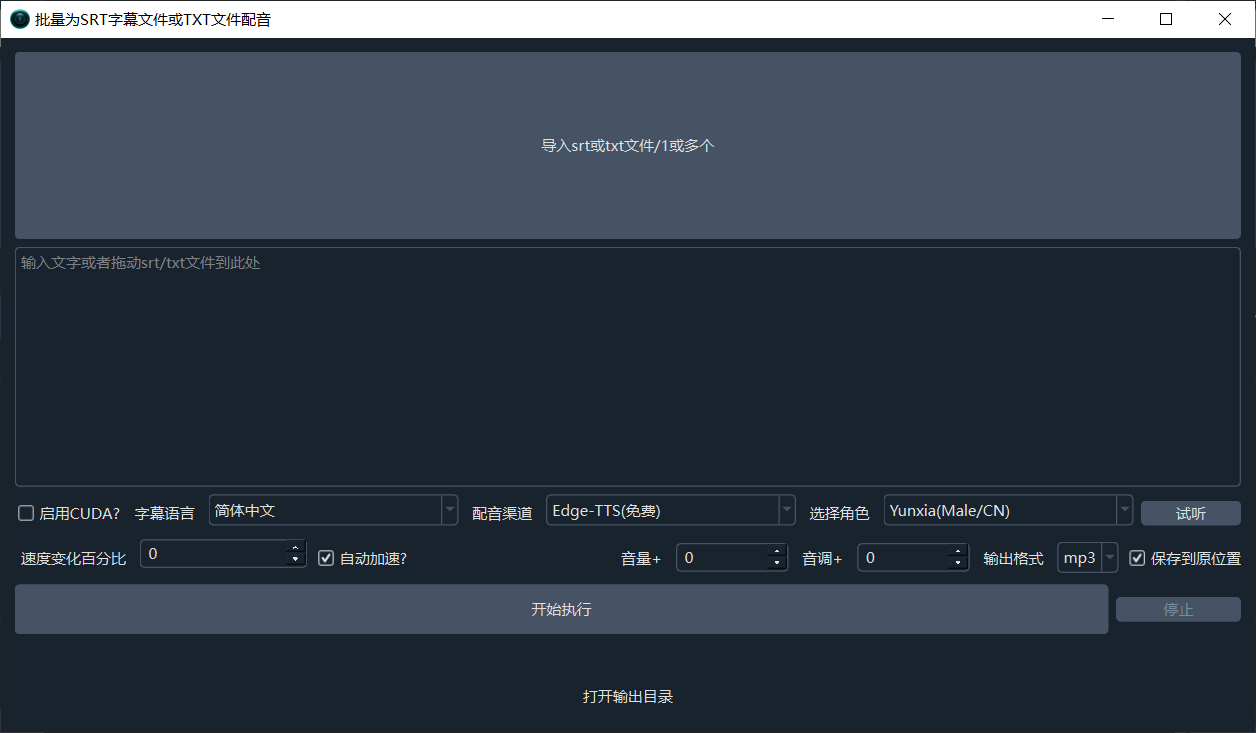
界面操作说明
- 顶部大按钮:可拖拽或点击导入一个或多个 srt/txt 文件
- 底部大文本框:可直接手动输入文本进行配音。如果你想为一大段文本配音,可复制粘贴到此;如果是为 srt 配音,请使用上方大按钮导入
- 字幕语言:即你的字幕语言,此选项决定可用使用哪些角色
- 配音渠道:默认 EdgeTTS(微软免费配音,支持所有语言)。其他渠道有付费在线 API、也有免费需本地部署的开源项目,根据需要选择。某些渠道需要在「菜单 → TTS 设置」中填写密钥 SK。全部配音渠道说明点击查看
- 选择角色:选择字幕语言和配音渠道后,可在此选择想使用的某个角色
- 试听配音:选择音色后,会显示试听配音按钮,点击可试听
- 速度变化百分比:默认 0,大于 0 代表在原本语速基础上加快百分比,例如
10代表加快 10%,-10即代表语速减慢 10% - 自动加速:不同语言、不同角色说话语速快慢不同,自然无法保证配音时长恰好等于原字幕时长,选中该复选框,若配音时长大于字幕时长,将强制加速缩短配音时长到字幕区间内
- 删字幕间静音:两条字幕之间通常有空隙,若选中,则删除空隙,声音直接相连,仅当未选择「自动加速」时有效
- 音量+:逻辑同「速度变化百分比」类似,大于 0 则音量增加该百分比,小于 0 则降低
- 音调+:默认 0,范围为
-50到50,音调从沉闷到尖锐变化 - 输出格式:默认输出 wav 音频,可选 mp3、m4a
- 保存到原位置:若选中,将把生成的配音音频保存到原始 srt 字幕文件所在位置
- 打开输出目录:点击打开生成的配音音频所在文件夹
可用的 TTS 渠道
pyVideoTrans 内置了多种 TTS 渠道,以下是常用的几类:
| 类型 | 渠道 | 特点 |
|---|---|---|
| 免费 | Edge-TTS | 微软免费接口,支持所有语言,效果自然 |
| 本地内置 | Qwen3-TTS | 阿里开源模型,支持中英日韩等 |
| 本地内置 | ChatterBox | 支持 20+ 种语言,效果优秀 |
| 本地内置 | MOSS-TTS-Nano | 支持多语言 |
| 本地内置 | Piper | 轻量级本地 TTS |
| 本地部署 | GPT-SoVITS | 支持声音克隆 |
| 本地部署 | F5-TTS | 支持声音克隆 |
| 在线 API | OpenAI TTS | 需要 API 密钥 |
| 在线 API | Azure TTS | 需要 Azure 账号 |
更多渠道请查看 配音渠道一览。
常见问题
Q: 配音后的音频时长和字幕不匹配怎么办?
选中「自动加速」选项,软件会自动将过长的配音加速到匹配字幕时长。
Q: 如何使用声音克隆?
在配音渠道中选择支持克隆的渠道(如 F5-TTS、GPT-SoVITS 等),并在角色列表中选择 clone。详情请参考 原声克隆与多角色配音。
Q: 配音结果有杂音或机械感?
尝试降低语速百分比,或更换发音角色。如果使用了声音克隆,请确保参考音频质量良好(5-10 秒,清晰无噪音)。