配音渠道:OmniVoice-TTS
一、什么是 OmniVoice
OmniVoice 是一款先进的零样本多语言 TTS 模型,具有以下特点:
- 超多语言支持:支持 600 多种语言
- 高质量语音:生成的语音自然流畅
- 语音克隆:支持基于参考音频克隆音色
- 推理速度快:具有卓越的推理速度
从 pyVideoTrans v3.98-0403 版本起,已支持使用 OmniVoice 进行配音。
OmniVoice 开源地址:https://github.com/k2-fsa/OmniVoice
二、前置条件
| 条件 | 说明 |
|---|---|
| pyVideoTrans 版本 | ≥ v3.98-0403 |
| 操作系统 | Windows(整合包)、Linux/macOS(源码部署) |
| 硬件 | 建议有 NVIDIA 显卡(GPU 加速) |
| 网络 | 首次启动需从 huggingface.co 下载模型(国内需镜像或科学上网) |
三、Windows 整合包(推荐新手)
下载
- 百度网盘下载:https://pan.baidu.com/s/1e6nHkq69TvUQe5VE02V-eg?pwd=1234
- HuggingFace 下载:https://huggingface.co/mortimerme/repocollect/resolve/main/omnivoice-0528.7z?download=true
启动
- 下载
.7z文件后解压 - 双击
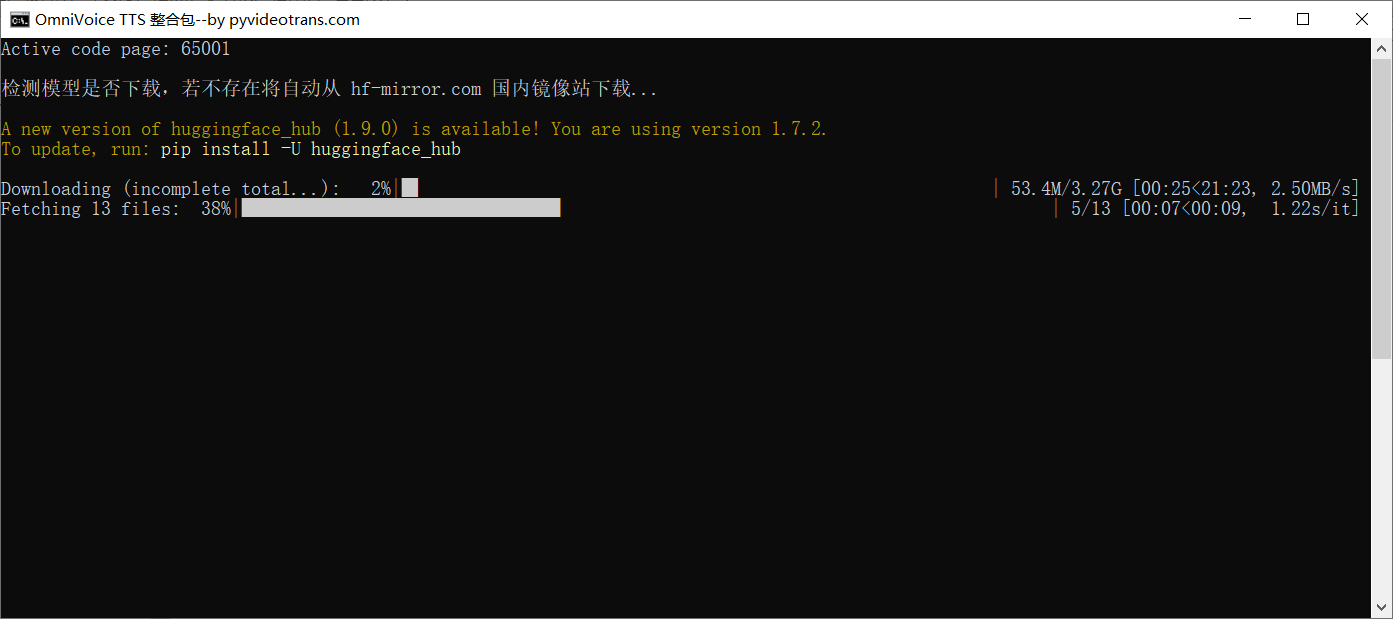
start.bat - 等待启动成功,成功标志是出现并停留在下图界面:

第一次启动将下载模型,默认从国内镜像站 https://hf-mirror.com 下载。源站 huggingface.co 国内无法直接访问,需科学上网。
四、MacOS/Linux 源码部署
第一步:下载源码
- 点击 OmniVoice 官方代码仓库 下载源码
- 点击首页中部的绿色
<>Code按钮,再点击Download ZIP - 解压后进入含有
pyproject.toml的文件夹(通常在OmniVoice-master内)
第二步:安装 uv
打开终端命令行执行安装命令:
curl -LsSf https://astral.sh/uv/install.sh | shWindows 用户:可点击下载 uv 压缩包,解压后将
uv.exe和pyproject.toml放在一起。
第三步:安装依赖
在 pyproject.toml 所在文件夹内打开终端,执行:
uv sync国内安装较慢,可使用镜像加速:
uv sync --default-index "https://mirrors.aliyun.com/pypi/simple"第四步:设置模型下载镜像
模型网站 huggingface.co 国内无法直接访问,需设置镜像:
Windows:
set HF_ENDPOINT=https://hf-mirror.comMacOS/Linux:
export HF_ENDPOINT=https://hf-mirror.com第五步:启动接口
uv run omnivoice-demo --ip 0.0.0.0 --port 8081五、在 pyVideoTrans 中使用
配置步骤
- 打开 pyVideoTrans 软件
- 点击菜单 → TTS设置 → OmniVoice-URL
- 填写地址:
http://127.0.0.1:8081 - 在下方角色列表中填写参考音频及其对应文本
参考音频格式
音频文件名.wav#音频对应的文字内容示例:假设已有音频 nverguo.wav(纯净的女儿国王说话声),将其放在 pyVideoTrans 软件下的 f5-tts 文件夹内,在设置界面填写:
nverguo.wav#这里填写说话的文字内容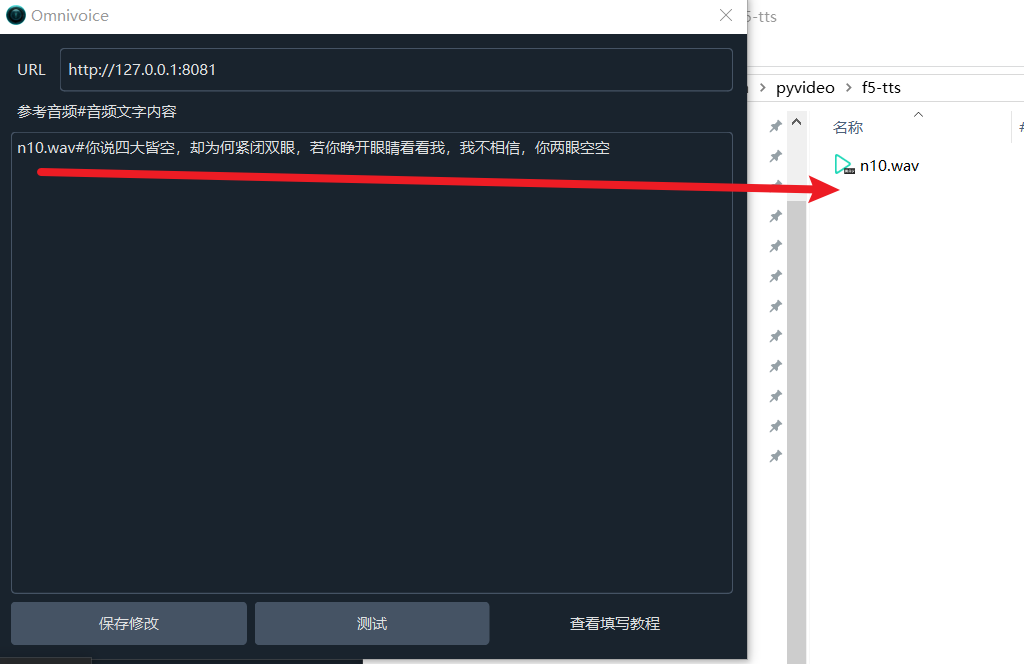
- 点击「测试」,若提示 OK 则保存,即可使用
六、在 Google Colab 上使用
也可以打开 该网址 直接在 Colab 上使用:
- 点击上方「全部运行」
- 等待最底部单元格出现类似
https://xxxxxxxx.gradio.live网址 - 点击打开可在浏览器里使用
- 复制该地址到 pyVideoTrans 菜单 → TTS设置 → OmniVoice-URL 中
七、参考音频要求
| 项目 | 要求 |
|---|---|
| 格式 | WAV 格式(推荐) |
| 时长 | 3~10 秒(最佳) |
| 内容 | 发音清晰,无背景噪音 |
| 放置位置 | pyVideoTrans 根目录下的 f5-tts 文件夹 |
源码代码验证(
_omnivoice.py):OmniVoice 使用/_clone_fnGradio API 端点,支持 60+ 种语言代码映射,内置重试机制(tenacity)。另外还支持 OmniVoice-Studio(端口 3900),使用 REST API/generate端点。
八、常见问题
1. 源码部署时看不到 pyproject.toml?
解压后默认会显示一个 OmniVoice-master 文件夹,点击进去会看到 pyproject.toml 或 pyproject,所有操作均需要在此文件夹内进行。
2. 提示 uv 不是内部或外部命令?
说明未安装 uv,或未放入系统环境。Windows 用户 点击下载 uv 压缩包,解压后复制 uv.exe 粘贴到 pyproject.toml 所在目录内。其他系统直接执行安装命令。
3. 下载模型很慢最终失败?
默认从 huggingface.co 下载,国内无法打开。需设置模型镜像源:
Windows:
set HF_ENDPOINT=https://hf-mirror.comMacOS/Linux:
export HF_ENDPOINT=https://hf-mirror.com4. uv sync 执行失败?
模块安装默认从国外下载,可使用国内阿里镜像源:
uv sync --default-index "https://mirrors.aliyun.com/pypi/simple"5. 使用阿里镜像源还是失败?
可能缺少 MSVC 环境,请 按此方案安装 MSVC 环境。
6. 如何直接在网页使用 OmniVoice 进行配音?
启动完成后,直接在浏览器里打开 http://127.0.0.1:8081
7. 整合包里如何修改启动端口和模型镜像?
使用记事本打开 start.bat:
- 如不想使用国内下载镜像,直接删除
set "HF_ENDPOINT=https://hf-mirror.com"这行 - 如想修改启动端口,修改
set "PORT=8081"中的8081为你想要的端口