OpenAI语音识别API使用指南
什么是OpenAI语音识别?
OpenAI语音识别是利用OpenAI提供的API将音频或视频中的语音转换为文字的功能。pyVideoTrans集成了OpenAI的语音识别接口,支持多种模型,包括经典的whisper-1和最新的gpt-4o-transcribe系列,能够为视频自动生成准确的字幕。
前提条件
- 一个付费的OpenAI账号(API使用需要付费)
- 有效的OpenAI API Key
- pyVideoTrans软件版本 v2.59 或更高(对于自动检测语言功能)
配置OpenAI API
在OpenAI官网 https://platform.openai.com 登录你的账号,进入API Keys页面创建一个新的API Key。
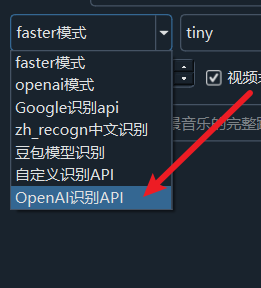
打开pyVideoTrans软件,进入菜单栏的“语音识别设置”,选择“OpenAI语音识别api”选项。
在配置窗口中:
- API Key:粘贴你的OpenAI API Key
- API Base URL:如果使用官方OpenAI API,保持默认;如果使用第三方代理,填写相应的URL
- 代理设置:如果需要代理访问,在相应字段配置代理地址
点击保存按钮完成配置。
支持的模型
OpenAI语音识别支持以下模型:
- whisper-1:经典的Whisper模型,识别准确,适合大多数场景
- gpt-4o-transcribe:基于GPT-4o的转录模型,性能更优
- gpt-4o-mini-transcribe:GPT-4o的轻量版转录模型,速度更快
- gpt-4o-transcribe-diarize:支持说话人分离的转录模型,可区分不同说话人
对于中文识别,建议使用gpt-4o-transcribe或whisper-1以获得良好效果。
最佳配置建议
- 模型选择:根据需求选择合适的模型。如果需要说话人分离,选择gpt-4o-transcribe-diarize。
- 提示词设置:在配置中可以设置提示词(prompt),例如提供专业术语或上下文,以提高识别准确度。
- 语言设置:除非确定语言,否则建议使用自动检测选项。
- 分段策略:对于长视频,软件会自动使用VAD(语音活动检测)进行分段处理。
自动检测语言功能
在pyVideoTrans v2.59版本后,原始语言下拉框中新增了“自动检测”选项。
- 使用场景:当不确定视频语言或语言不属于支持的24种语言时,可选择“自动检测”。
- 工作原理:程序会分析视频前30秒的声音片段来判断语言,并用于整个视频。
- 注意事项:
- 尽量避免使用该选项,尤其是视频前30秒没有清晰说话声时
- 某些发音相似但书写不同的语言(如简体中文和繁体中文)可能无法准确区分
常见错误与解决方案
错误:API Key无效或余额不足 确保使用的OpenAI账号有付费额度,且API Key正确。
错误:无法连接到API 检查网络连接,如果需要代理,请正确配置代理设置。
错误:识别结果不准确 尝试更换模型,或设置更相关的提示词。对于中文,确保选择正确的语言选项。
错误:处理时间过长 这是正常现象,尤其是对于长视频。软件会自动分段处理以提高效率。
高级功能
- 说话人分离:使用gpt-4o-transcribe-diarize模型时,可以自动区分不同说话人。
- 分段时间戳:对于官方API,使用verbose_json格式获取详细的时间戳信息。
- 第三方API支持:通过设置不同的API Base URL,可以使用兼容的第三方服务。
通过以上配置,你就可以在pyVideoTrans中使用OpenAI的语音识别服务了。OpenAI的模型在多种语言上都有出色的表现,特别适合高质量字幕制作。