ElevenLabs语音识别使用指南
什么是ElevenLabs语音识别?
ElevenLabs是一家领先的人工智能语音技术公司,其推出的语音识别模型scribe支持99种语言的音频转录。pyVideoTrans集成了ElevenLabs的语音识别接口,让用户可以利用其高精度识别能力生成字幕,且提供免费额度,无需信用卡即可开始使用。
前提条件
- 一个有效的电子邮箱地址,用于注册ElevenLabs账号
- 稳定的网络连接
- pyVideoTrans软件版本 v3.59 或更高
注册与获取API Key
访问ElevenLabs官网:https://elevenlabs.io/ ,使用邮箱注册账号。注册过程简单,无需手机验证、无需绑卡、无需充值。
登录后,进入设置页面:https://elevenlabs.io/app/settings/api-keys
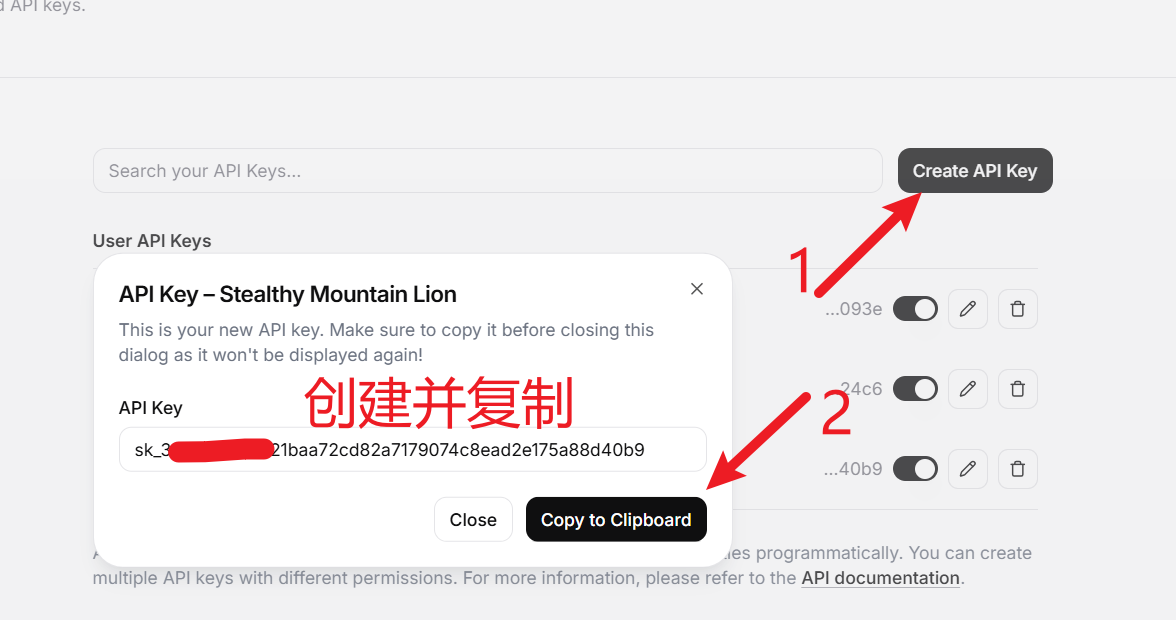
点击“Create API Key”按钮创建一个新的API Key,复制并保存该Key。
在pyVideoTrans中配置ElevenLabs
打开pyVideoTrans软件,进入菜单栏的“TTS设置”,选择“Elevenlabs.io”选项。
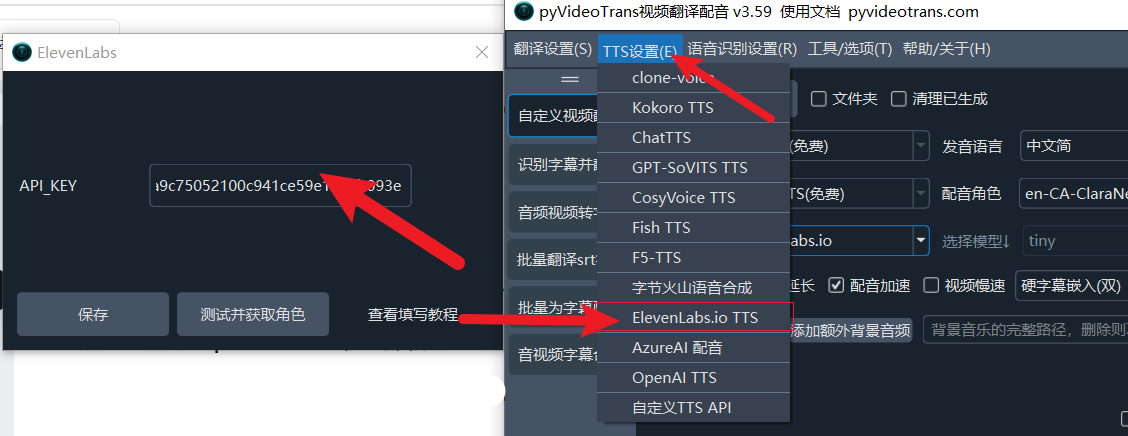
在配置窗口中:
- API Key:粘贴上一步复制的ElevenLabs API Key
- 其他设置保持默认即可
点击保存按钮完成配置。
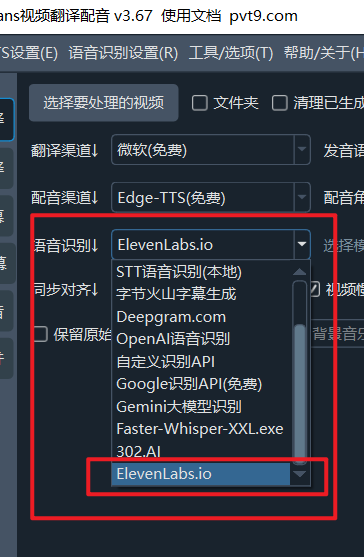
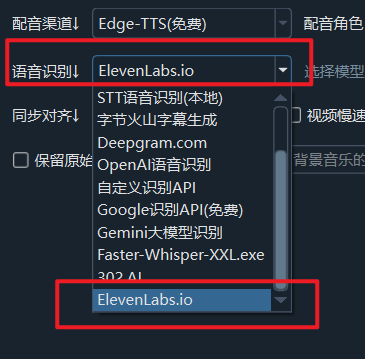
在软件主界面的语音识别渠道中选择“Elevenlabs.io”,即可使用ElevenLabs进行语音识别。
支持的模型与选项
ElevenLabs提供两种语音识别模型:
- scribe_v2:最新模型,支持指定语言代码(language_code),识别准确度更高
- scribe_v1:经典模型,无需指定语言代码,自动检测语言
高级选项包括:
- diarize:启用说话人分离功能,可区分音频中的不同说话人
- word-level timestamps:提供单词级别的时间戳,用于精确分段
最佳配置建议
- 模型选择:对于中文识别,建议使用scribe_v2并指定语言代码为“zh”,以获得最佳效果。
- 说话人分离:如果视频中有多个说话人,启用diarize选项。
- 分段策略:软件会根据标点符号、静音时长(>=200毫秒)和段落长度(>=500毫秒)自动分段。
- 文件大小:单个文件限制为1GB,确保视频文件不超过此大小。
常见错误与解决方案
错误:API Key无效 确保复制的Key正确,且没有多余的空格。
错误:文件过大无法处理 ElevenLabs单文件限制为1GB,如果视频文件过大,请先压缩或分割。
错误:识别结果不准确 尝试指定正确的语言代码,或使用不同的模型(如从v1切换到v2)。
错误:网络连接问题 确保网络可以正常访问elevenlabs.io,必要时配置代理。
在网页中直接使用ElevenLabs
除了在pyVideoTrans中使用,你也可以直接在ElevenLabs网页中进行语音识别:
访问Speech to Text页面:https://elevenlabs.io/app/speech-to-text
登录账号后,点击左侧的“Speech to text”选项。
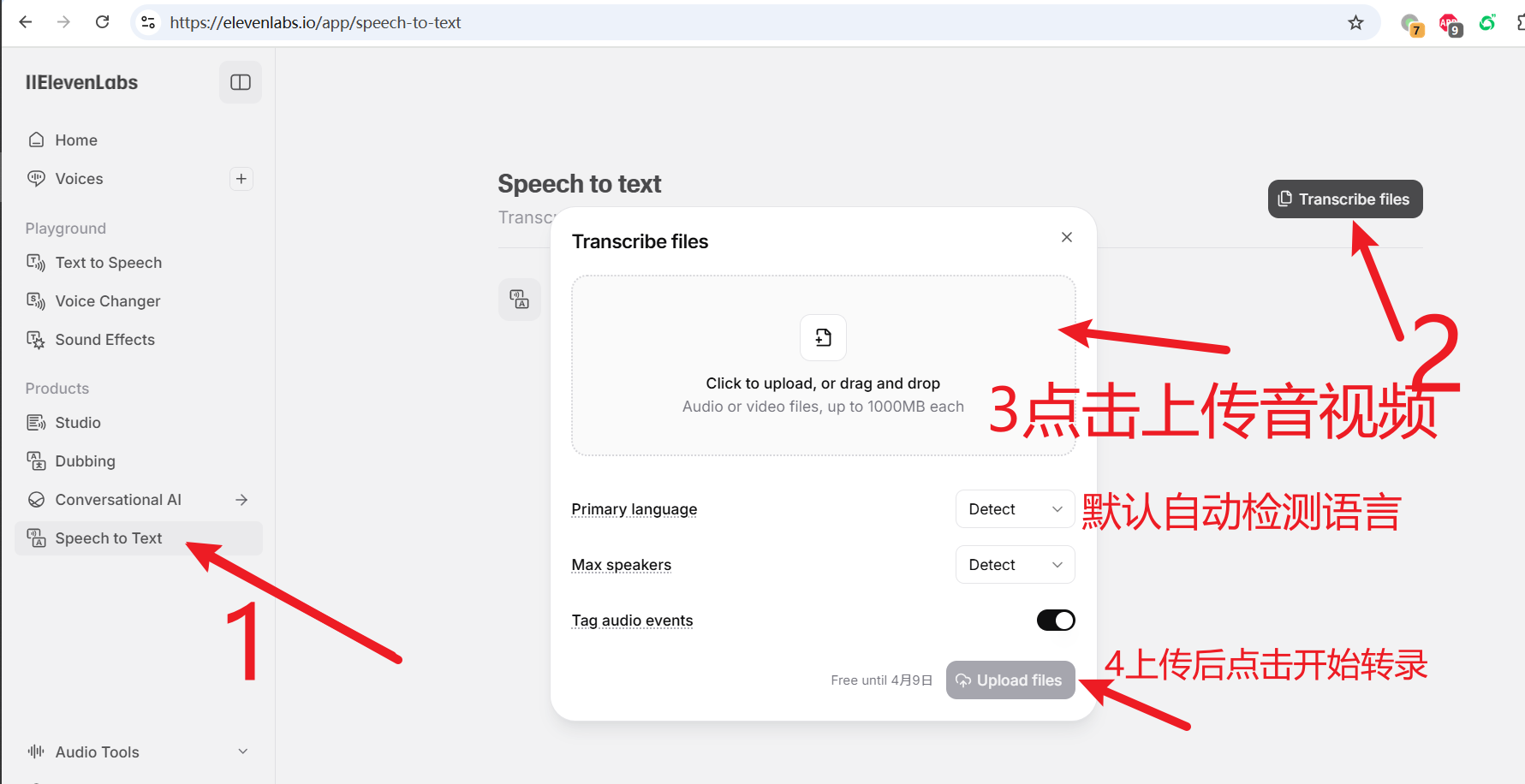
上传音频或视频文件,点击“Transcribe”按钮开始转录。
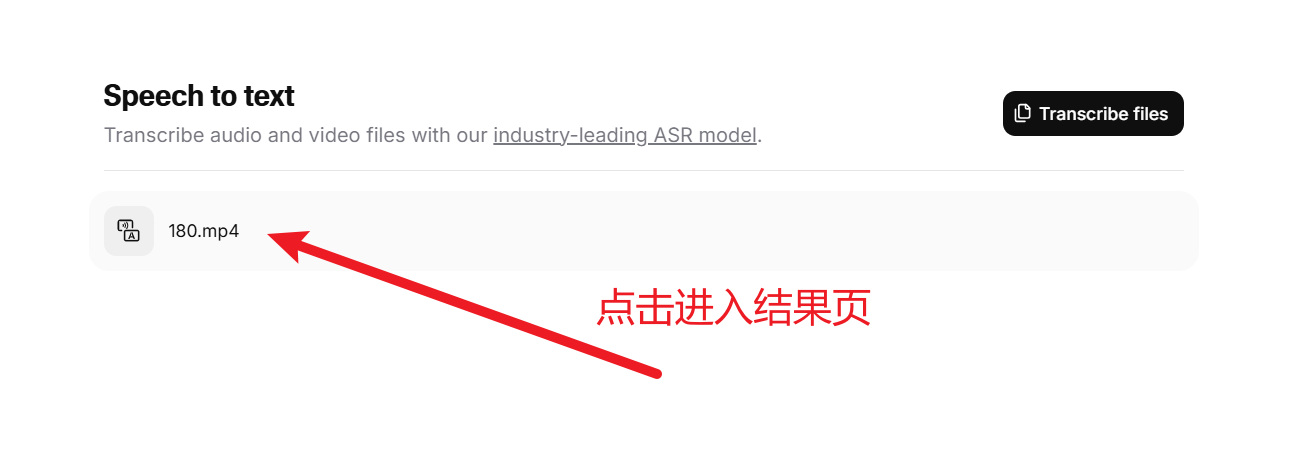
等待转录完成后,点击显示的文件名进入转录结果页,可以查看和下载字幕。

注意事项
- ElevenLabs提供免费额度,无需信用卡即可注册使用。
- 支持99种语言,包括中文、英文、日文等多种语言。
- 语音识别基于先进的AI模型,识别准确度高,适合高质量字幕制作。
- 如果遇到任何问题,可以参考ElevenLabs官方文档或pyVideoTrans帮助中心。
通过以上步骤,你就可以在pyVideoTrans中使用ElevenLabs的语音识别服务了。ElevenLabs的模型在多种语言上都有出色的表现,特别是其免费额度让用户体验更加友好。