v3.64 has made some minor optimizations to the software, mainly focusing on segmentation during speech recognition and reducing voiceover errors.
Adjust Subtitle Duration during Speech Recognition
The principle of speech recognition is to segment the entire audio into several small fragments based on silent intervals. Each fragment may be 1 second, 5 seconds, 10 seconds, or 20 seconds long, etc., and then transcribe these small fragments into text, and then combine them into subtitle form.
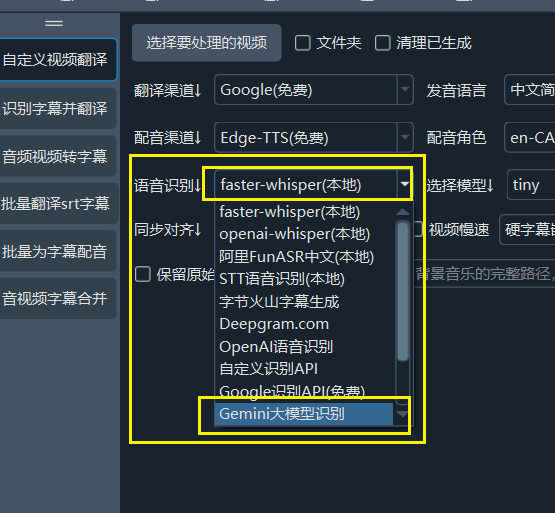
When using faster-whisper mode or GeminiAI as the speech recognition channel, there may be situations where the subtitle recognition results are too long (a large string of text) or too fragmented. At this time, you can adjust the segmentation parameters according to the speech characteristics. The following parameters are mainly involved:
Find the Menu → Tools/Options → Advanced Options → faster/openai speech recognition adjustment interface, as shown in the figure below
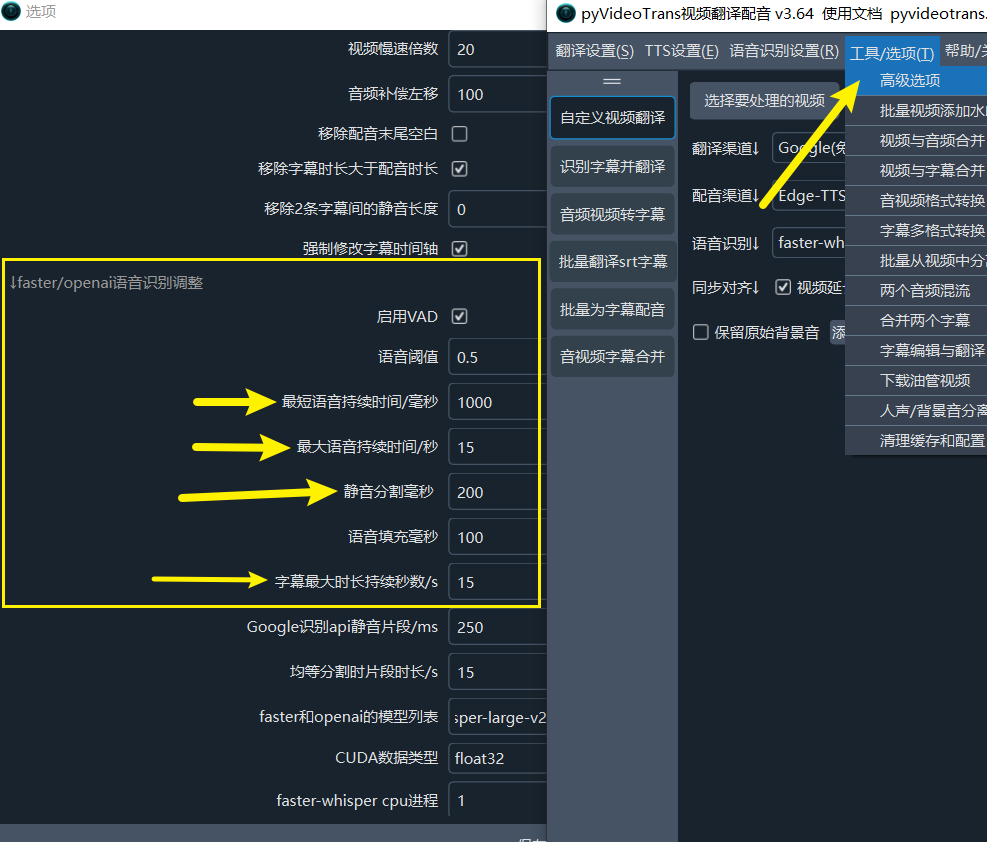
- Silence Separation Milliseconds (Note the unit is milliseconds): This is the basis for speech segmentation. Only when the duration of a certain silent segment reaches or exceeds the set value, will it be segmented here. For example, setting it to 200 means that it will only be segmented when the silent interval reaches or exceeds 200 milliseconds. If the speech speed is fast and the pauses are short, this value can be lowered; conversely, if the speech speed is slow, it can be appropriately increased.
- Minimum Speech Duration/Milliseconds (Note the unit is milliseconds): Only segments exceeding this set duration will be segmented into a subtitle. For example, setting it to 1000ms means that the shortest segmented subtitle will not be less than 1000 milliseconds, to avoid overly fragmented subtitles.
- Maximum Speech Duration/Seconds (Note the unit is seconds): Opposite to the previous item, it is used to limit the maximum duration of subtitles. For example, setting it to 15 means that if the segment duration reaches 15 seconds and a suitable segmentation point is not found, it will be forcibly segmented.
- Maximum Subtitle Duration in Seconds: This parameter is used to re-segment sentences after recognition is completed, to limit the subtitle length, and is not related to the segmentation during the speech recognition process.
edge-tts reduces the 403 error rate (also applicable to other voiceover channels)
Since voiceover requires connecting to Microsoft's API, 403 errors cannot be completely avoided. However, errors can be reduced by making the following adjustments:
Find the Menu → Tools/Options → Advanced Options → Voiceover Adjustment as shown in the figure below
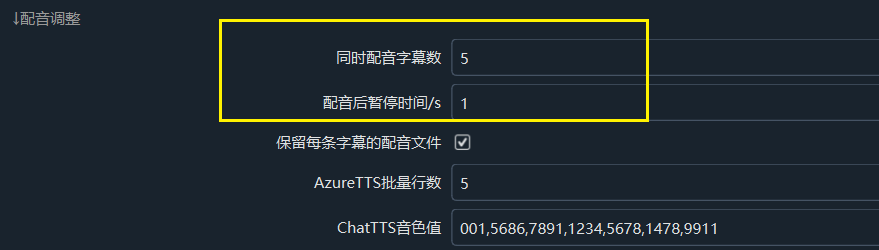
- Number of Subtitles to Voiceover Simultaneously: It is recommended to set this to 1. Reducing the number of subtitles to voiceover simultaneously can reduce errors caused by excessively high request frequency. This setting is also applicable to other voiceover channels.
- Pause Time After Voiceover/Seconds: For example, setting this to 5 means pausing for 5 seconds after completing voiceover for a subtitle before performing the next voiceover. It is recommended to set this value to 5 or higher to reduce the error rate by extending the request interval.
This is an open-source and free video translation, speech transcription, text voiceover, and subtitle translation software Open-source address
https://github.com/jianchang512/pyvideotransDocumentation site:https://pvt9.comThe software itself is free of charge and without revenue, relying on interest to support maintenance. If it is useful to you, donations are welcome to support it:https://pvt9.com/about